DATA 622 Meetup 1: What is Machine Learning?
2026-01-26
Welcome to DATA 622!
What to Expect
- There is a course website
Research on LLMs in Education

What I have Seen

- Do not let yourself become reliant on LLMs
Textbooks
- Standard text for people coming into machine learning from a variety of areas

Textbooks
- Hands on Machine Learning Very practical more CS style book that focuses on python implementations

Textbooks
- DevOps for Data Science Accessible book to start learning some things needed to get models in production

Events This Week!

Events This Week!

Example: Transaction Fraud Detection
Problem: Fraudulent transactions are costly
Can be several % of total revenue, billions of dollars

Transaction Fraud Detection

Transaction Fraud Detection
Can create a formula: \[ y = f(\mathbf{x}) \]
Transaction Fraud Detection
Can create a formula: \[ y = f(\mathbf{x}) = \mathrm{sign}\left(w_1x_1 + w_2x_2 + w_3x_3 + \cdots + w_n x_n \right) \]
Transaction Fraud Detection
Can create a formula: \[ y = f(\mathbf{x}) = \mathrm{sign}\sum_{i=1}^n w_ix_i \]
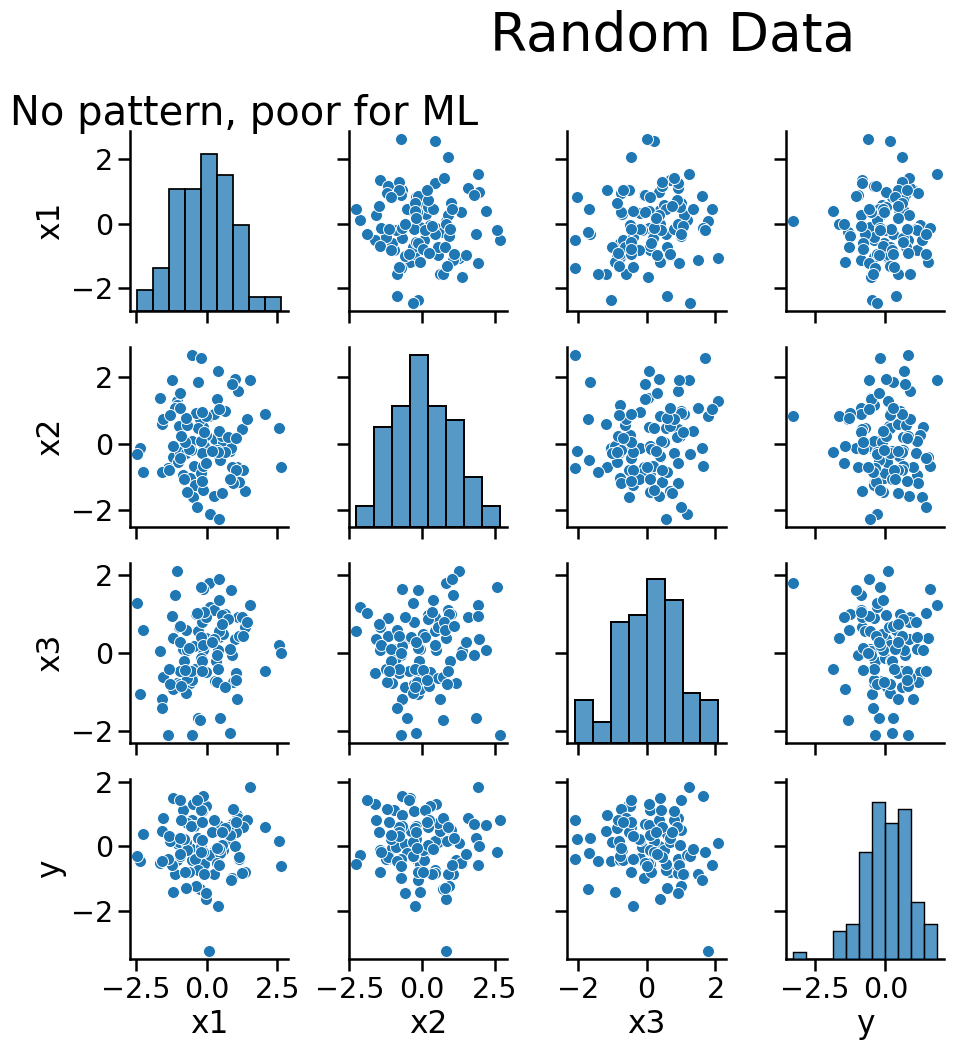
When to use Machine Learning?
- There is a pattern to learn
- There aren’t mathematical formulas that give you the answer already
- You have data
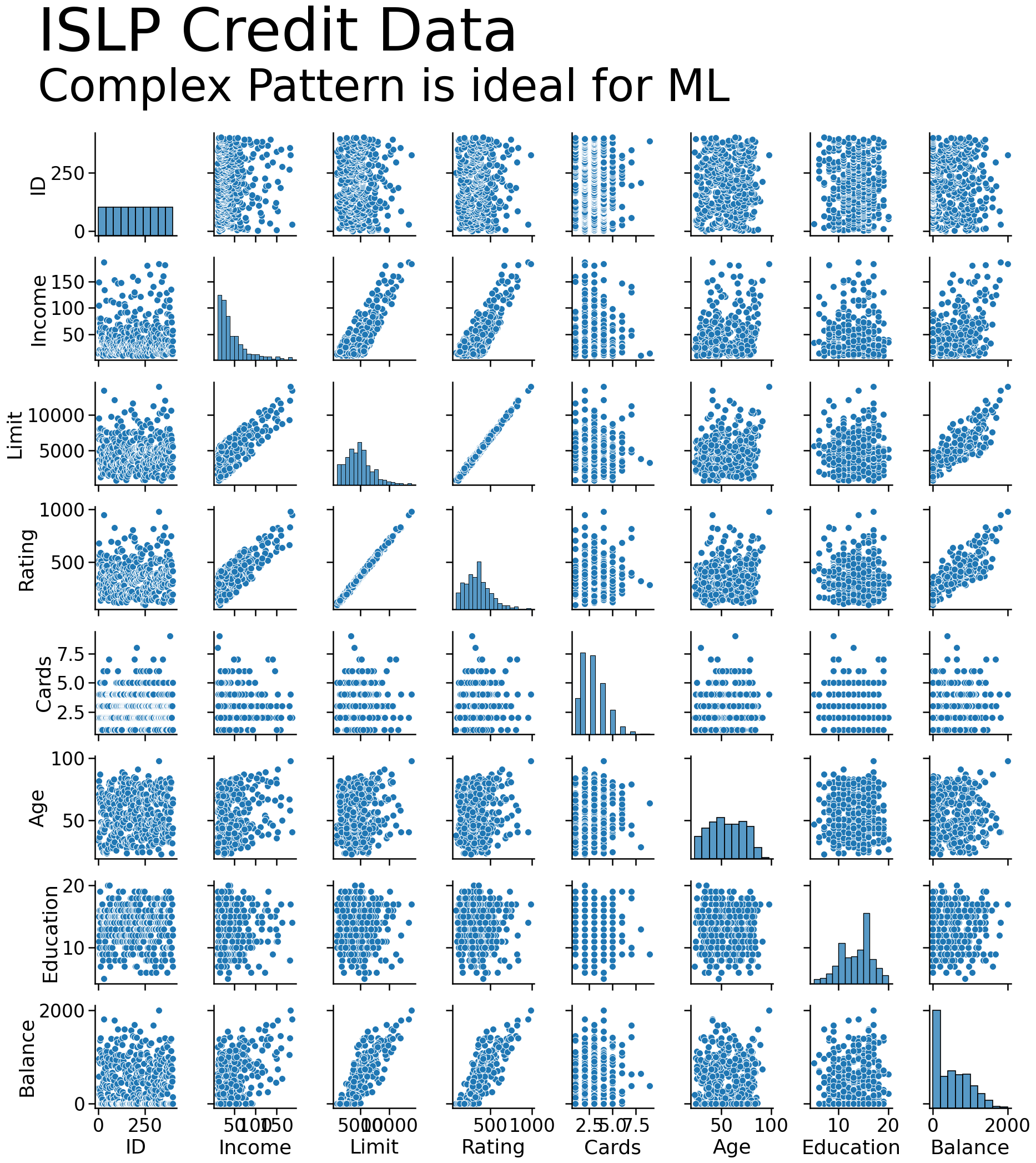
When to use Machine Learning?
- There is a pattern to learn
- There aren’t mathematical formulas that give you the answer already
- You have data
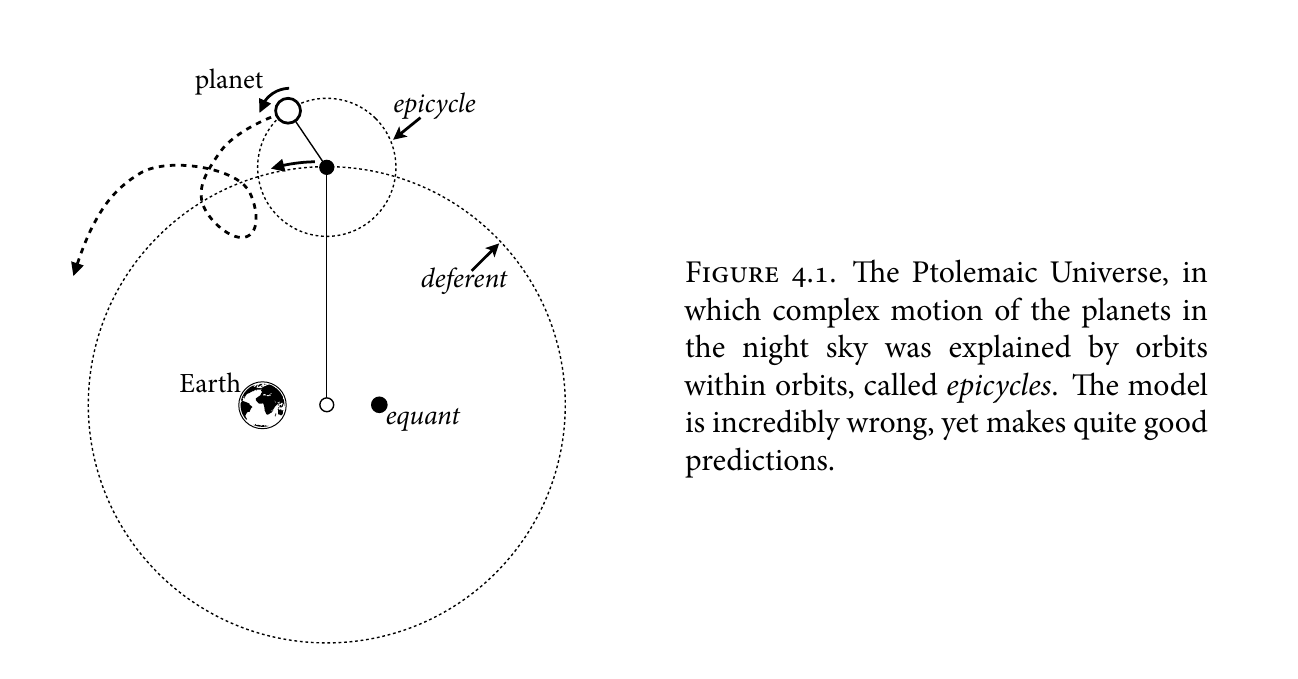
Statistical Rethinking
When to use Machine Learning?
- There is a pattern to learn
- There aren’t mathematical formulas that give you the answer already
- You have data
\[ \mathbf{F} = -\frac{Gm_1m_2\hat{\mathbf{r}}}{\|\mathbf{r}\|^2} \]
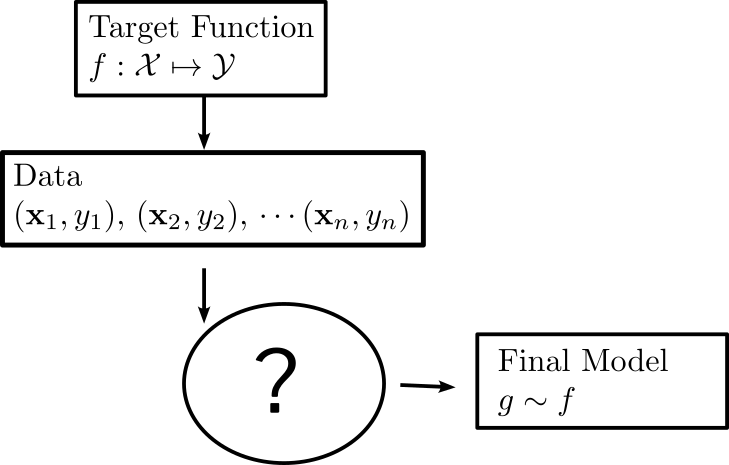
How the components fit together
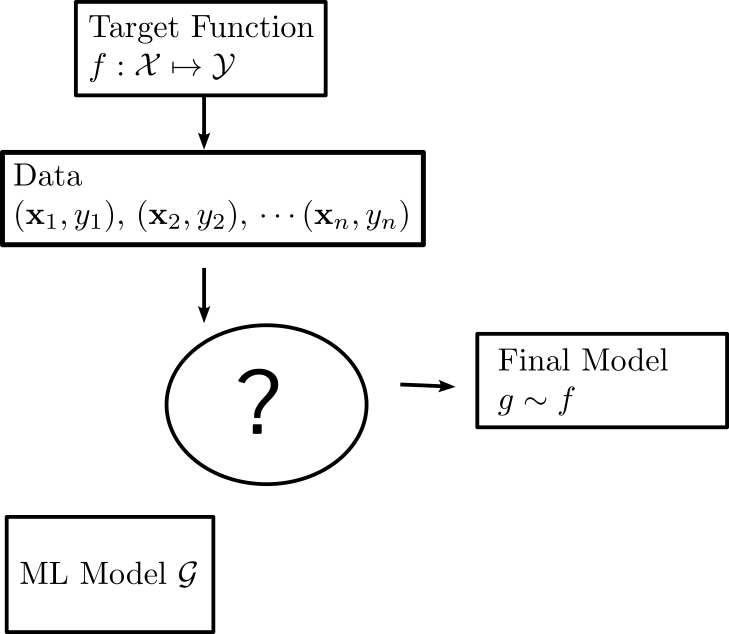
How the components fit together
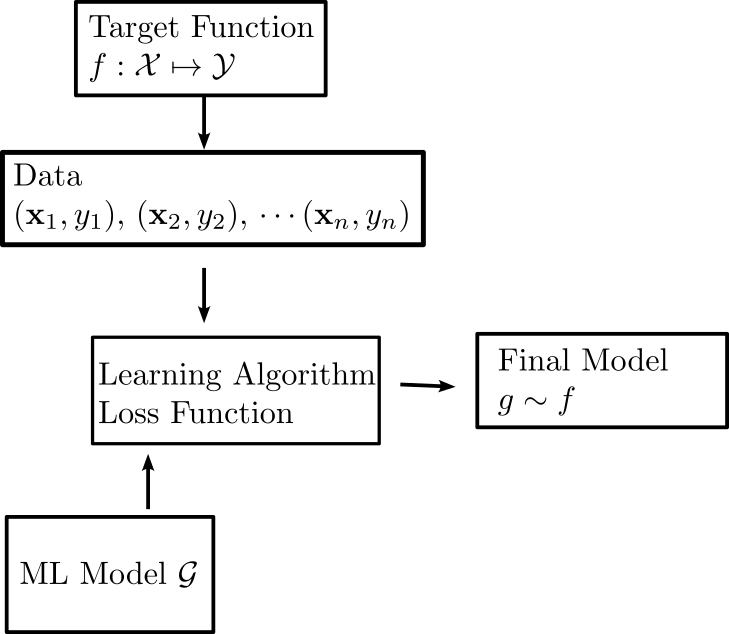
How the components fit together
Models
- The set \(\mathcal{G}\) can vary in complexity a lot
- Linear Models \(y=\mathbf{w}\cdot\mathbf{x}+x_0\)
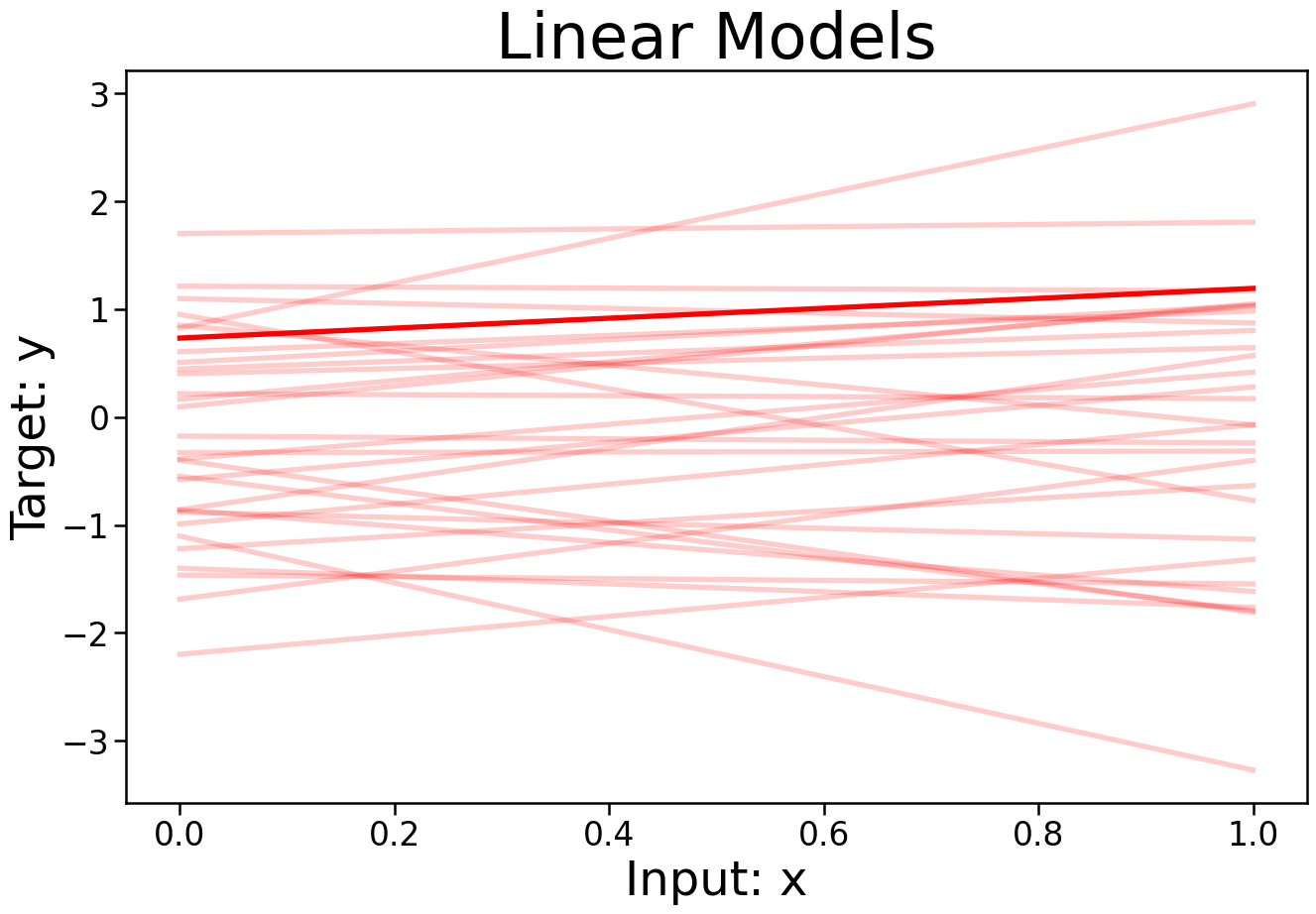
Models
- The set \(\mathcal{G}\) can vary in complexity a lot
- Decision Trees
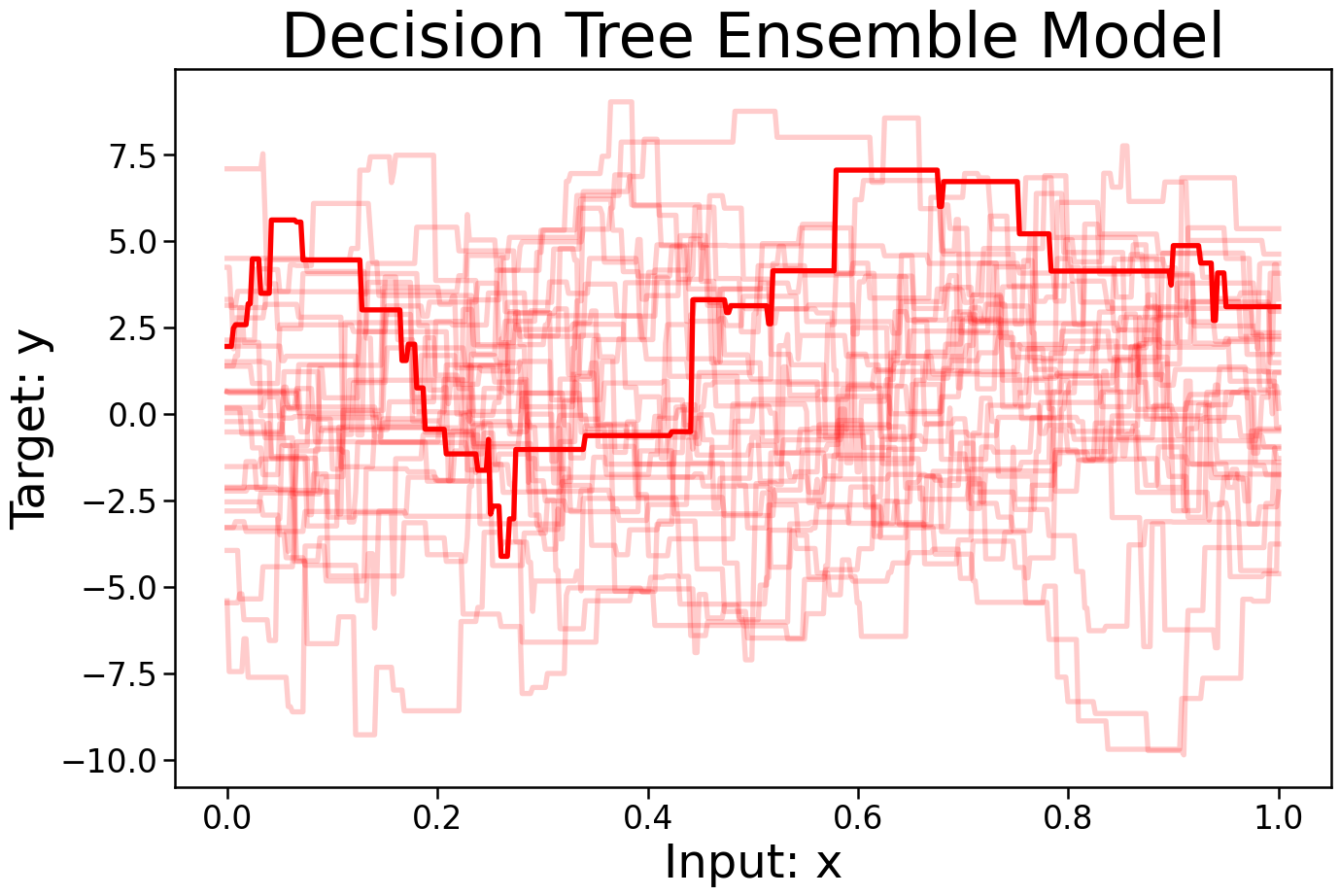
Learning Algorithms
- For some models (linear models, support vector machines, etc), exact formula or guaranteed algorithms exist
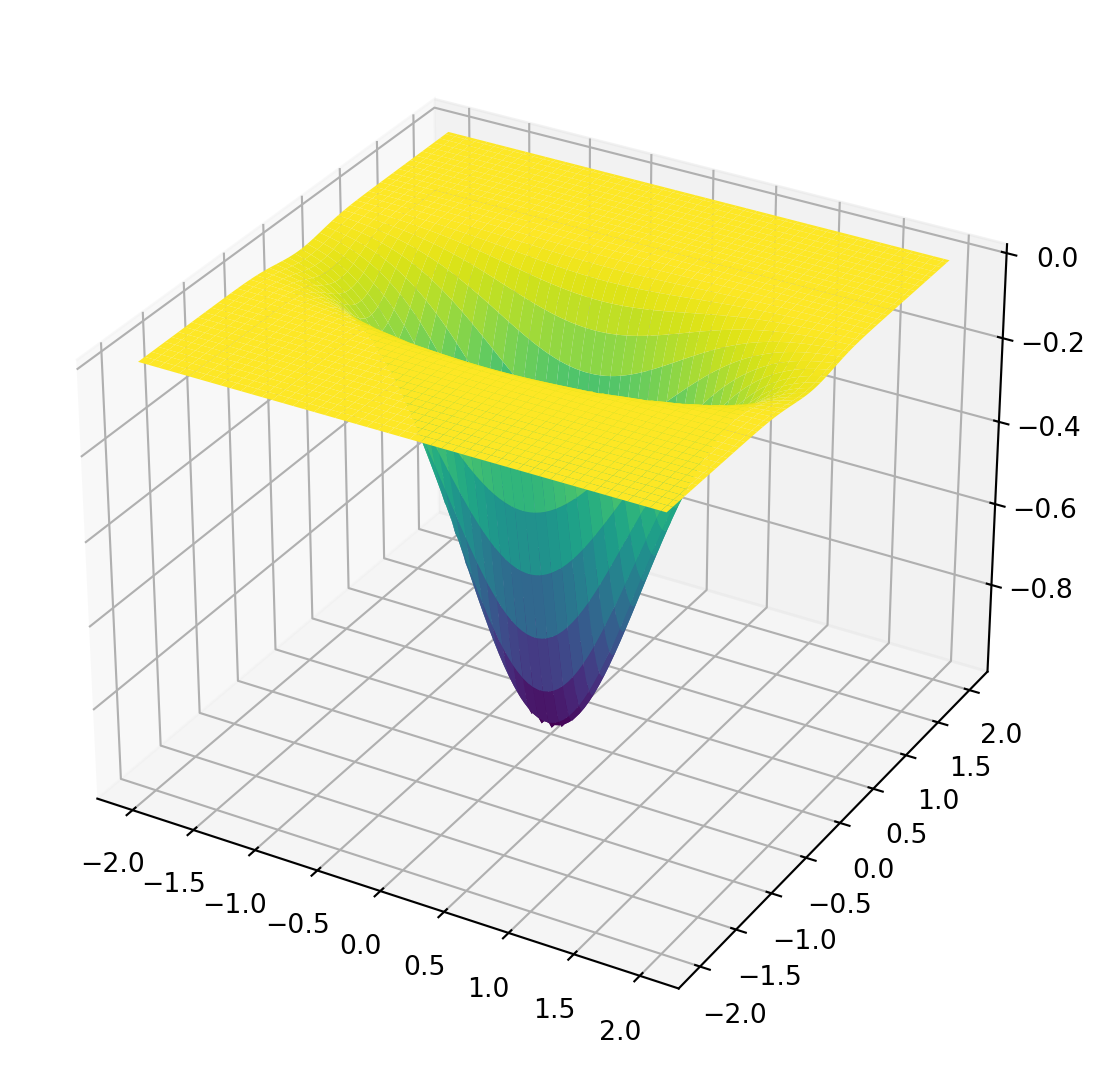
Learning Algorithms
- For fancy models, decision trees, neural networks, Gaussian Processes, no guarantee exists and the algorithm is a dark art
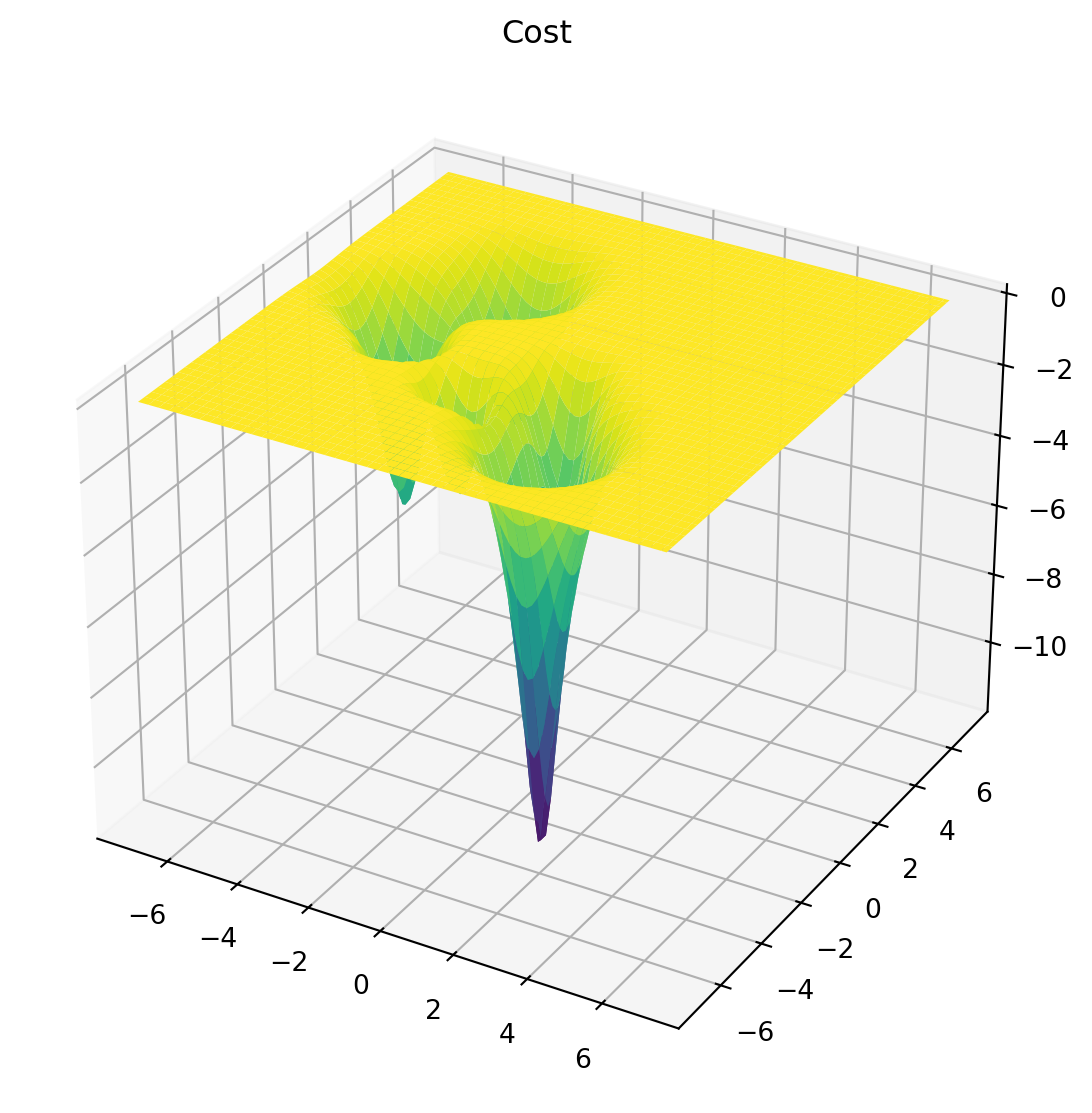
Goals of Modeling
- Different models are good for different goals
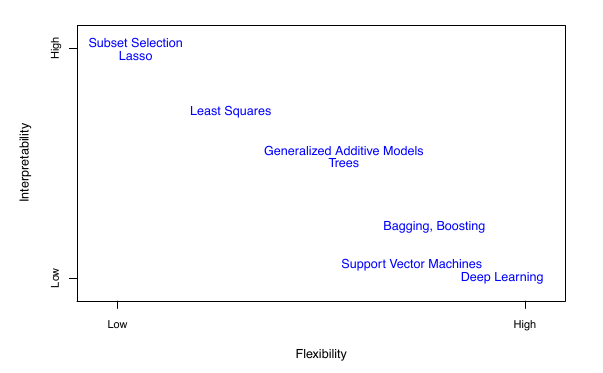
ISLP
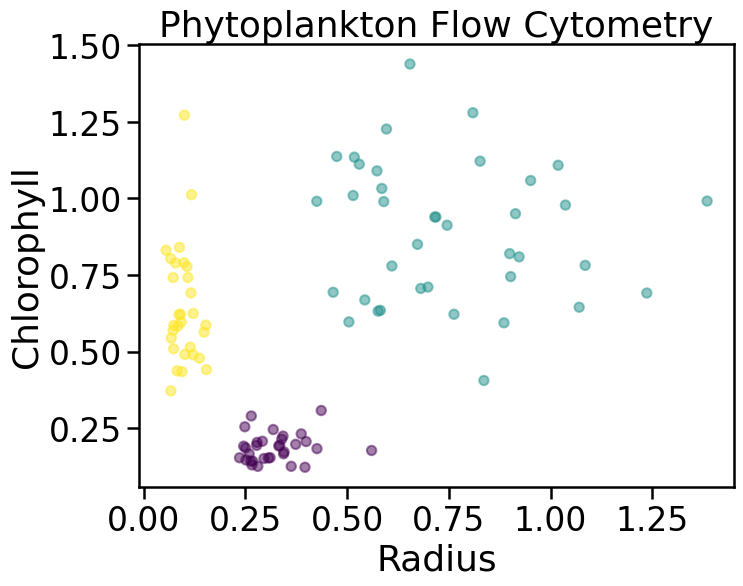
Unsupervised Learning
- In some problems, the label \(y\) is not known to us
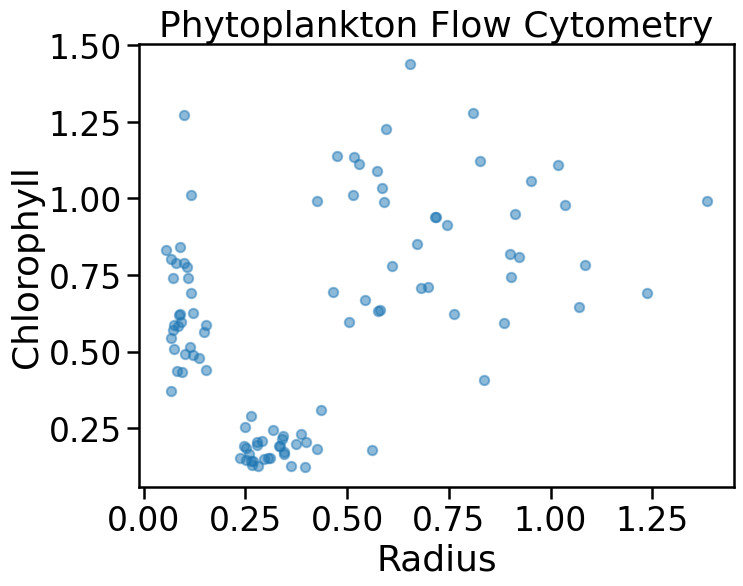
Unsupervised Learning
- Algorithms exist to group points together or reduce dimension
Thanks!
![]()