tensor([[1, 2],
[3, 4]])DATA 622 Meetup 12: Neural Networks
2026-04-20
Introduction to Neural Networks
- Invented originally to understand how the brain works
Source: wikipedia
Introduction to Neural Networks
- Was found to have an enormous number of applications
- Classification
- Pattern Recognition
- Generative Models
What is a Neuron?
- Neurons send and receive electrical signals
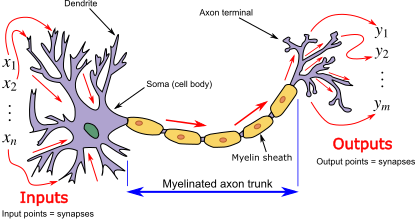
wikipedia
Connected Neurons
- They are connected to other neurons
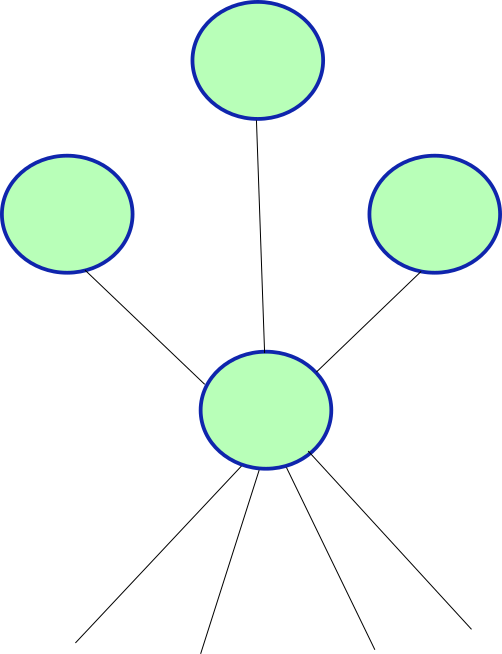
Connected Neurons
- They are connected to other neurons
- They respond to stimulus from senses and other neurons

Connected Neurons
- They are connected to other neurons
- They respond to stimulus from senses and other neurons
Connected Neurons
- They are connected to other neurons
- They respond to stimulus from senses and other neurons
- Cross a threshold before firing
Connected Neurons
- They are connected to other neurons
- They respond to stimulus from senses and other neurons
- Cross a threshold before firing
Connected Neurons
- They are connected to other neurons
- They respond to stimulus from senses and other neurons
- Cross a threshold before firing
- Neuronal Cascade is part of cognition
Single Neuron
- Single Neuron converts several inputs into an output:
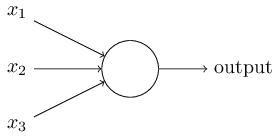
Nielson
Activation Functions
- Biology intuition:
- \(\phi=1\) when integrated inputs positive
- \(\phi=0\) or \(\phi=-1\) (doesn’t matter) when integrated input negative
- Leads to step/sigmoid functions:
Activation Functions to Know
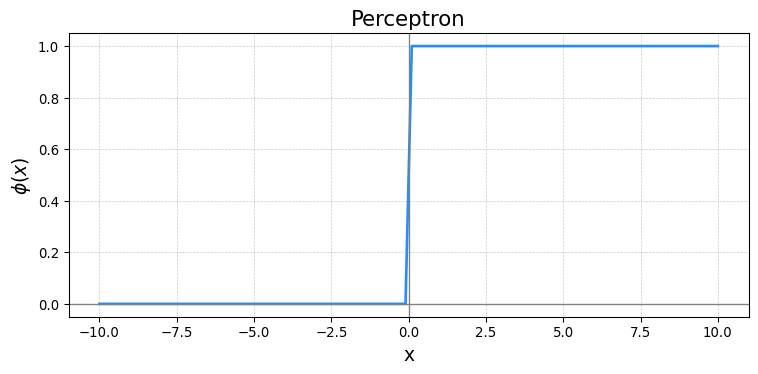
- Perceptron \[ \phi(x) = \cases{1& \text{if} \quad x\geq 0 \\ 0& \text{if} \quad x<0} \]
Activation Functions to Know
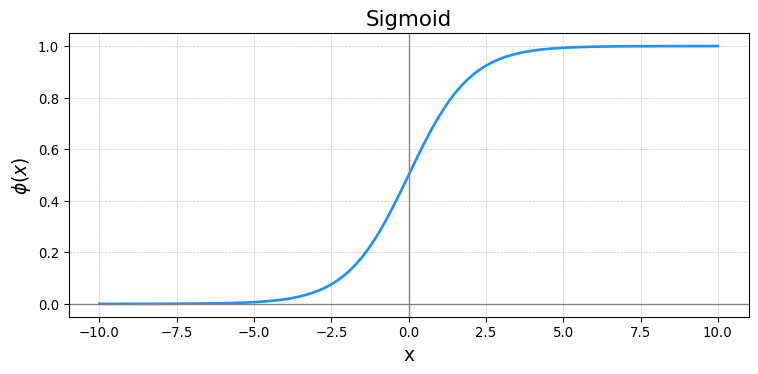
- Sigmoid Function
\[ \phi(x) = \frac{1}{1+e^{-x}} \]
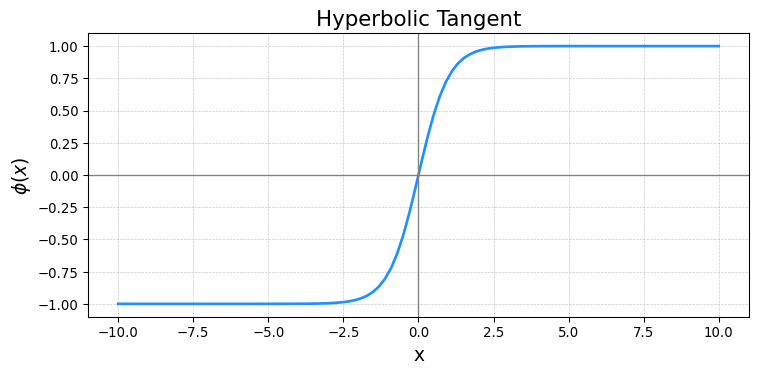
Activation Functions to Know
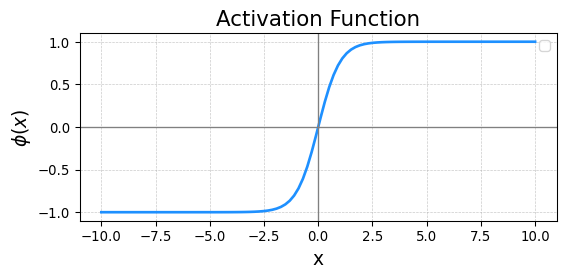
- Hyperbolic Tangent
\[ \phi(x) = \frac{e^x - e^{-x}}{e^x +e^{-x}} \]
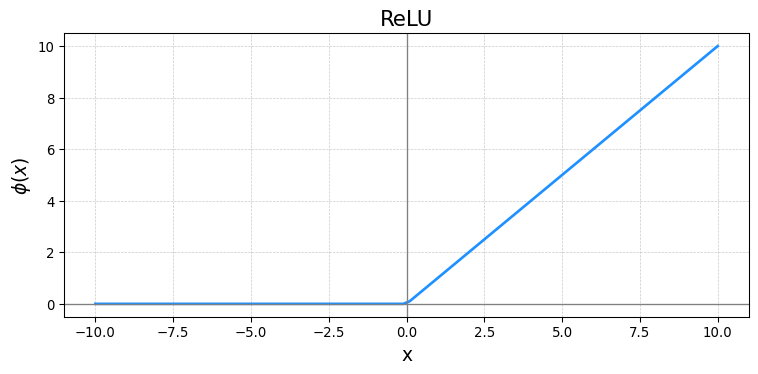
Activation Functions to Know
- Rectified Linear Unit (ReLU)
\[ \phi(x) = \cases{0& \text{if} \quad x\geq 0 \\ x& \text{if} \quad x<0} \]
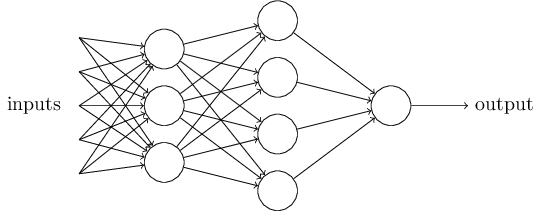
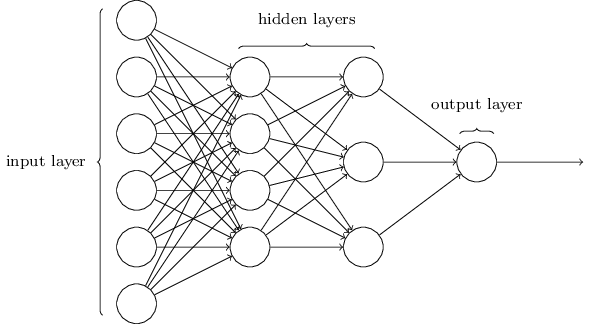
Feedforward Neural Networks
- Input layer, one neuron per input variable
- One neuron per target function
- Neurons organized in layers
Neural Network Considerations
- Even a small NN can be huge:
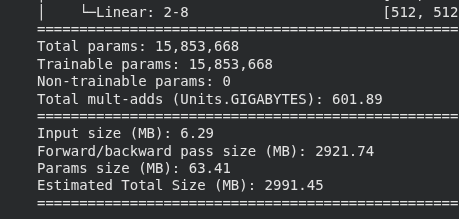
- Need lots of data
- Lots of different regularization
Loading Data
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.FashionMNIST('data/', train=True, download=True, transform=transform)
test_dataset = datasets.FashionMNIST('data/', train=False, transform=transform)
img, label = training_data[100]
plt.imshow(img.squeeze(),cmap="gray")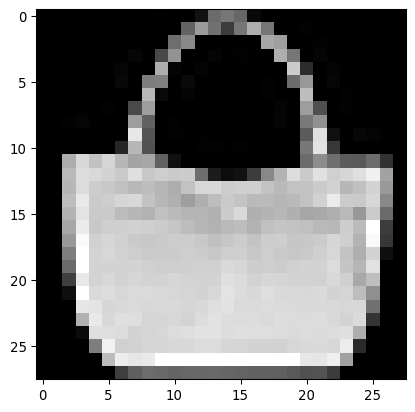
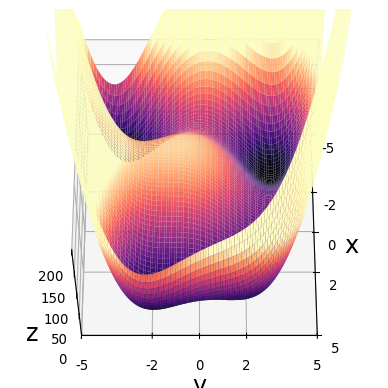
Optimization Basics
- Simplified loss landscape:
- Imagine more dimensions
Gradient Descent
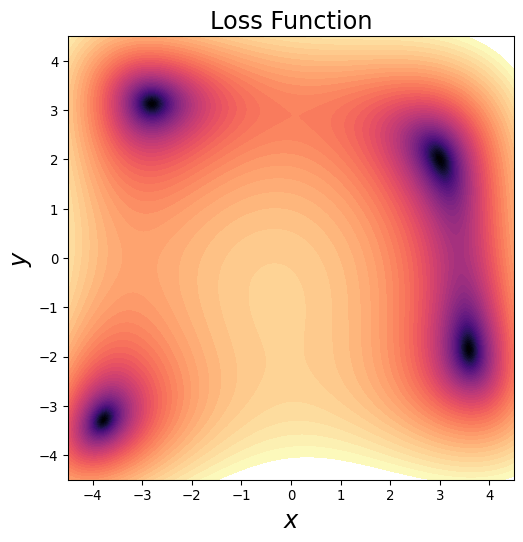
- Start at \(\mathbf{x}_0\)
- Find gradient \(\nabla \mathrm{loss}(\mathbf{x})\)
- \(\mathbf{x}_n = \mathbf{x}_{n-1} - \kappa \nabla\mathrm{loss}(\mathbf{x}_{n-1})\)
- \(\kappa\) is learning rate
What Learning Rate to Pick?
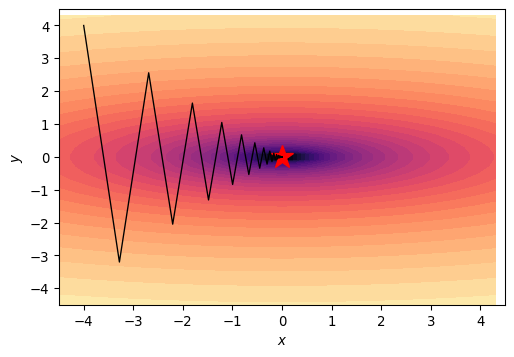
- Steepness discrepancy limits learning rate
- Most of the step is in wrong direction
Momentum
- Advanced algos use momentum, gives “memory” of past gradient
- Reduces effect of valley oscillation
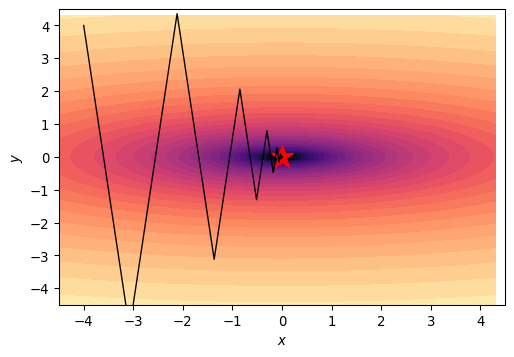
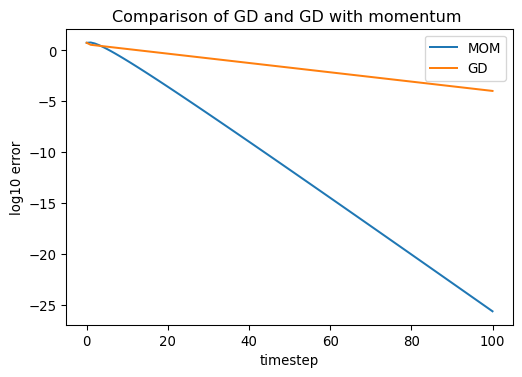
Stochastic Gradient Descent
- Common for optimization algorithms to “get stuck”
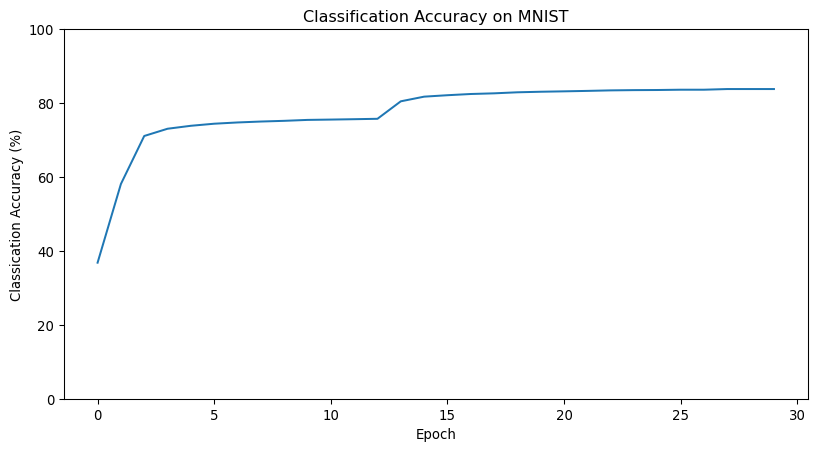
Stochastic Gradient Descent
- In low-D local minima are problematic
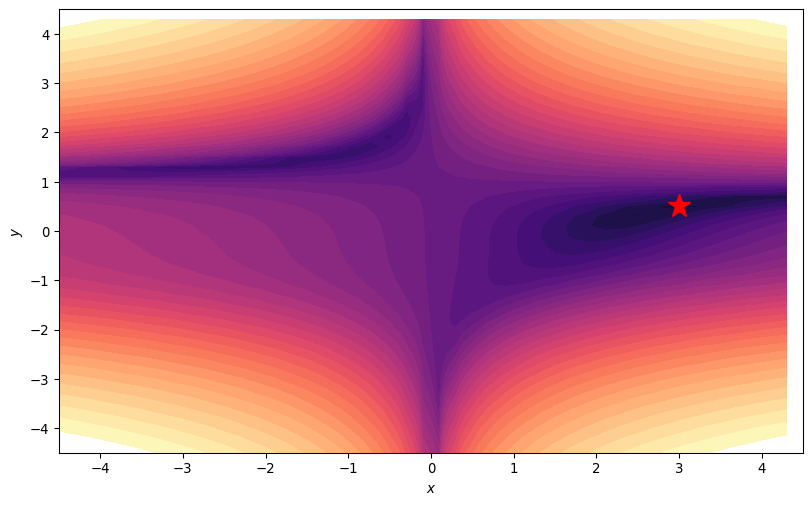
Stochastic Gradient Descent
- Trajectories get Stuck
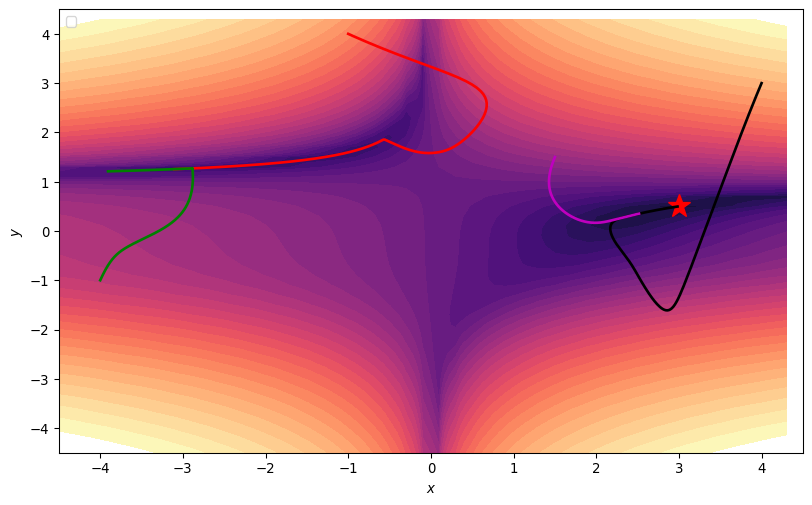
Stochastic Gradient Descent
Stochastic Gradient Descent
- In 2D, can just add noise
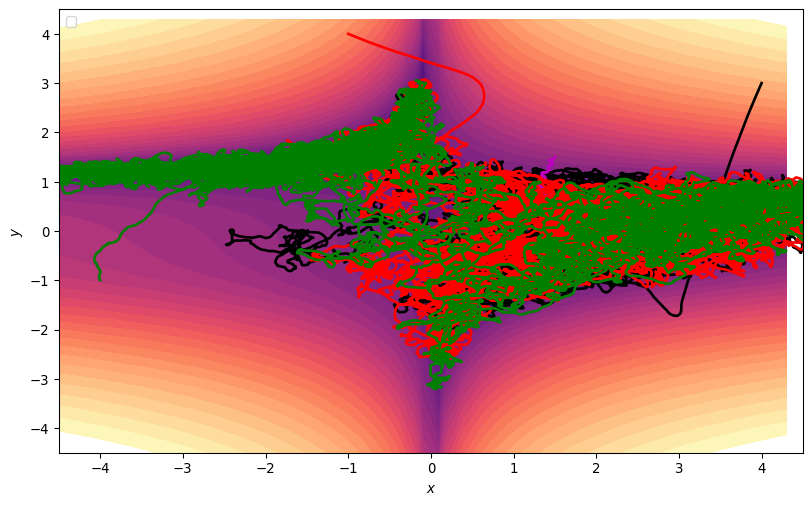
When and Why is ADAM good?
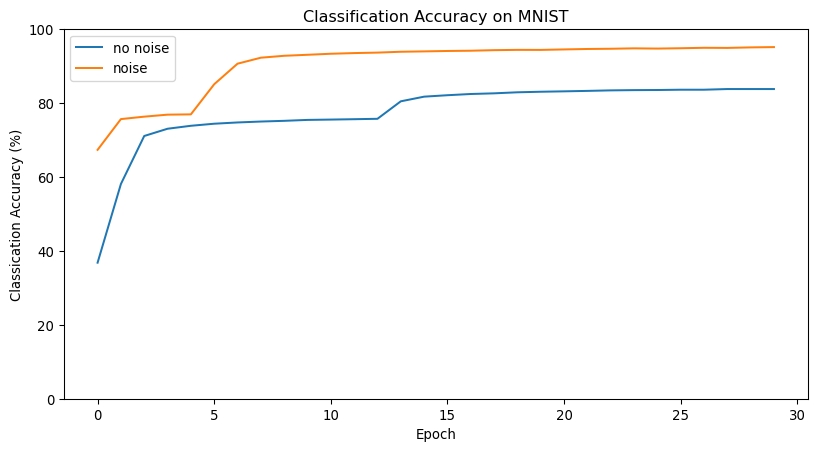
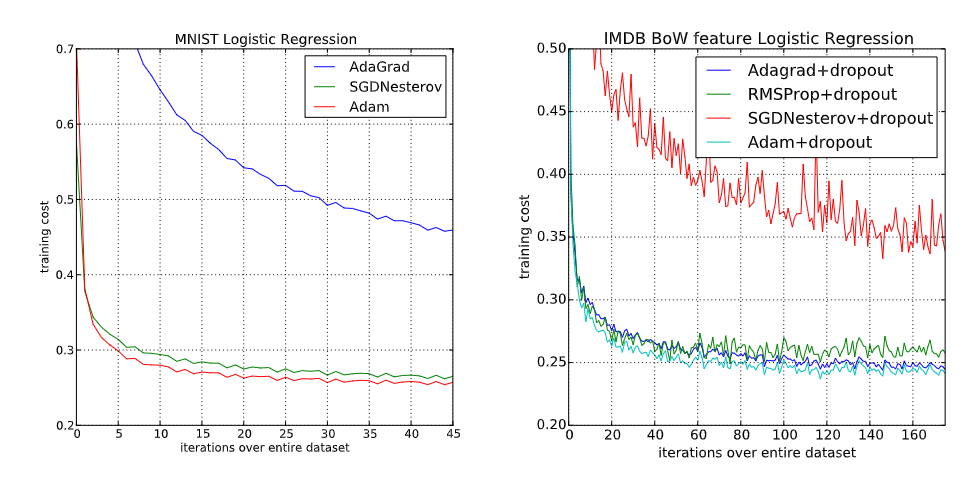
ADAM is much more robust to learning rate choices
ADAM is excellent when the gradient is sparse
ADAM is often the best in initial training stages
![]()
Thanks
![]()