DATA 622 Meetup 13: Neural Networks
2026-04-27
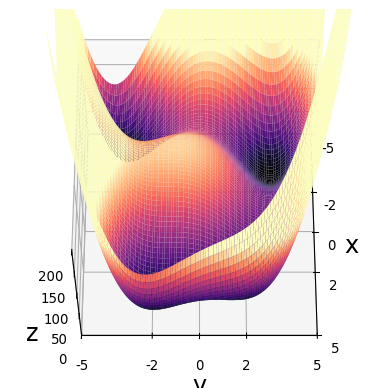
Gradient Descent
- Start at \(\mathbf{x}_0\)
- Find gradient \(\nabla \mathrm{loss}(\mathbf{x})\)
- \(\mathbf{x}_n = \mathbf{x}_{n-1} - \kappa \nabla\mathrm{loss}(\mathbf{x}_{n-1})\)
- \(\kappa\) is learning rate
What Learning Rate to Pick?
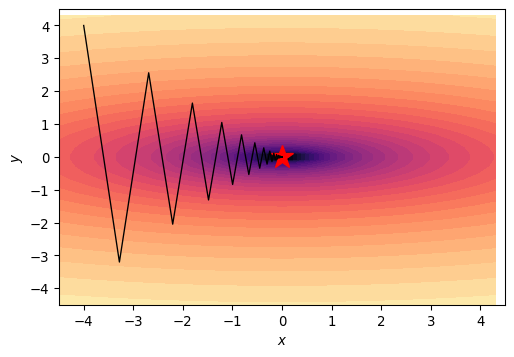
- Steepness discrepancy limits learning rate
- Most of the step is in wrong direction
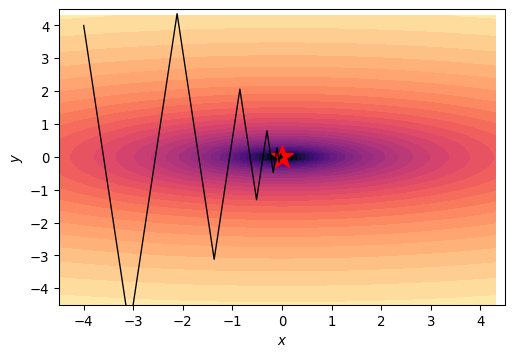
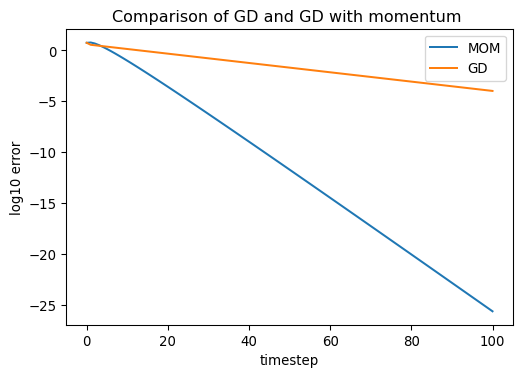
Momentum
- Advanced algos use momentum, gives “memory” of past gradient
- Reduces effect of valley oscillation
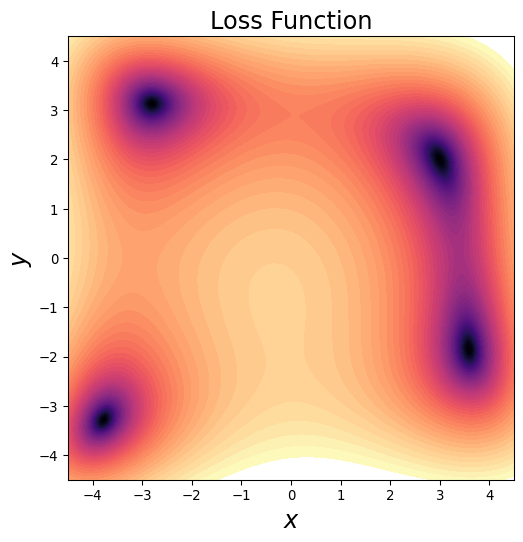
Stochastic Gradient Descent
- Common for optimization algorithms to “get stuck”
Stochastic Gradient Descent
- In low-D local minima are problematic
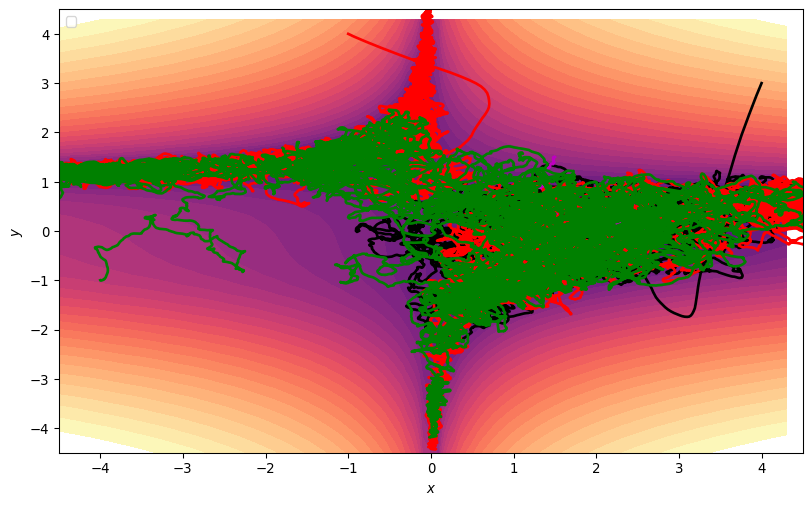
Stochastic Gradient Descent
- Trajectories get Stuck
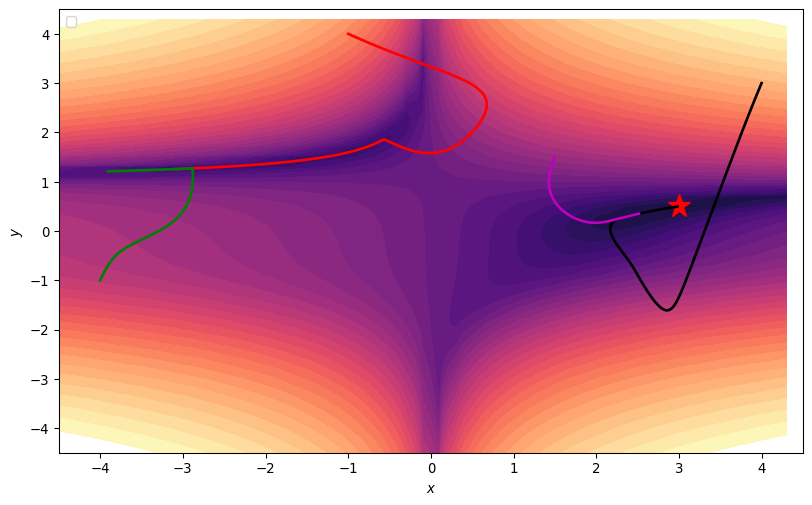
Stochastic Gradient Descent
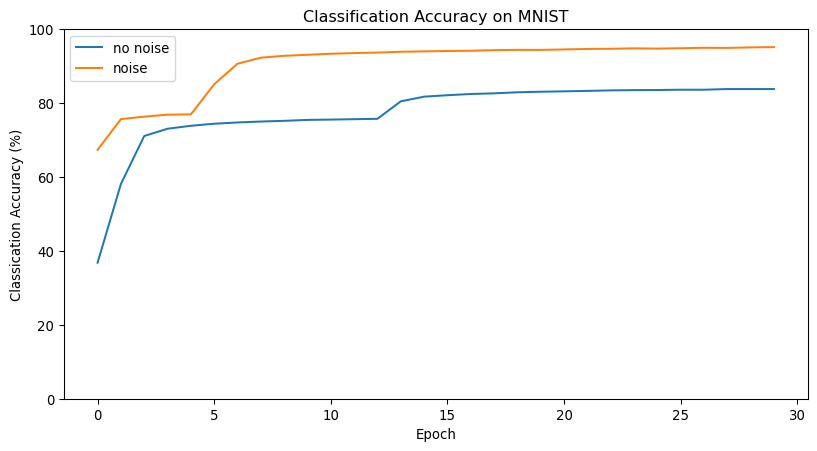
Stochastic Gradient Descent
- In 2D, can just add noise
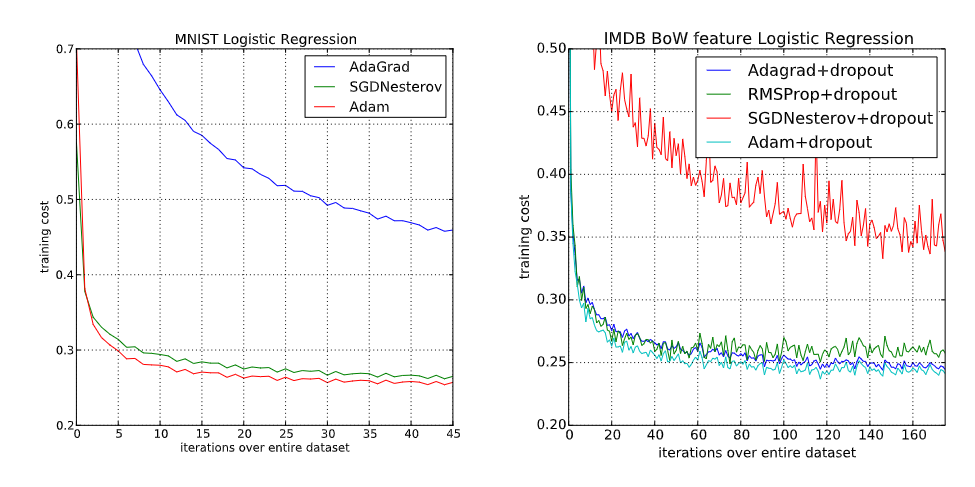
When and Why is ADAM good?
ADAM is much more robust to learning rate choices
ADAM is excellent when the gradient is sparse
ADAM is often the best in initial training stages
![]()
Network Architecture and Inductive Bias
- Fully Connected Networks don’t have much inductive bias
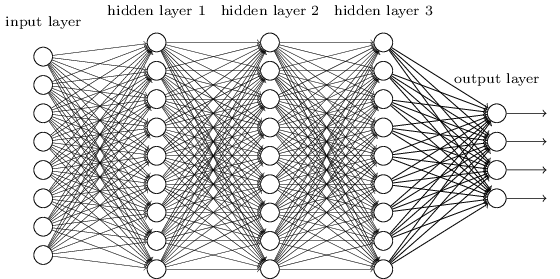
Image Recognition Bias and Symmetry
- Neural Network for image recognition
- This is a bicycle

Image Recognition Bias and Symmetry
- Neural Network for image recognition
- If we shift it it is still a bicycle

Image Recognition Bias and Symmetry
- Neural Network for image recognition
- If we shift it it is still a bicycle
Image Recognition Bias and Symmetry
- Neural Network for image recognition
- If we shift it it is still a bicycle

Image Recognition Bias and Symmetry
- Neural Network for image recognition
- If we shift it it is still a bicycle

Image Recognition Bias and Symmetry
- Neural Network for image recognition
- If we shift it it is still a bicycle
Image Recognition Bias and Symmetry
- Neural Network for image recognition
- We can even rotate it
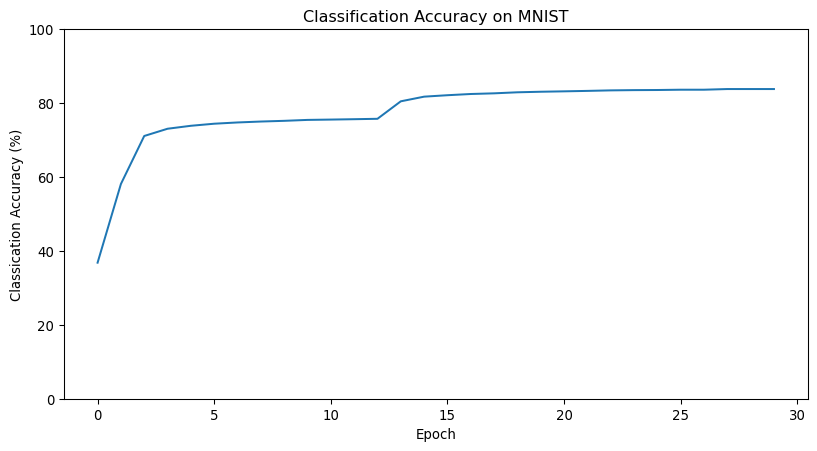
Accuracy of Fully Connected Networks
- Fully Connected Networks are not suited to image recognition
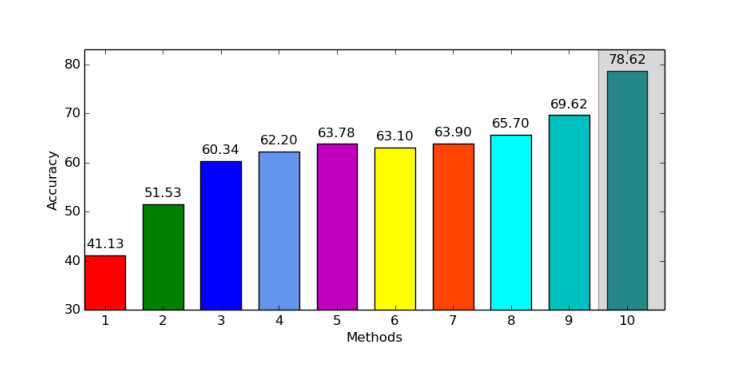
- Small well designed neural networks exceed 90% on CIFAR10
- Best networks exceed 99%
Convolution
- 1960s Q: How do we detect edges in images?
- 1960s A: Create an “archetype” image of an edge, and calculate the correlation of it with each part of the original image
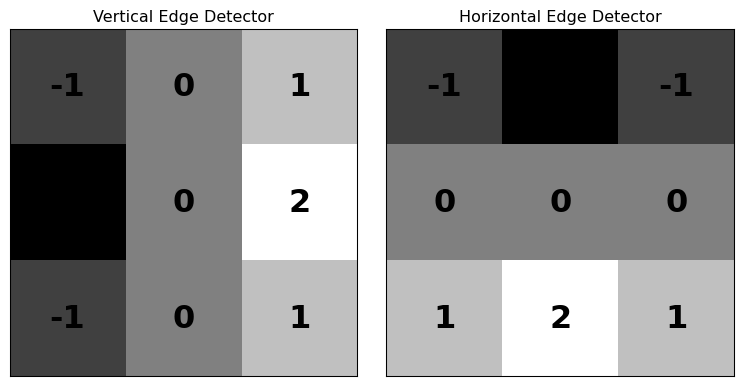
Applying the Convolution
- The convolution ‘kernel’ is like a pattern that is applied all over the target image
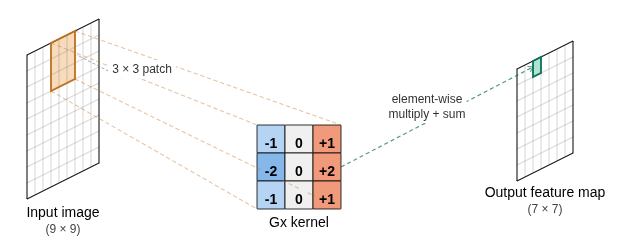
Convolution in Practice

Convolutional Neural Networks
- CNN Architecture:
- Layers are small, learned filters
- Feature map per layer
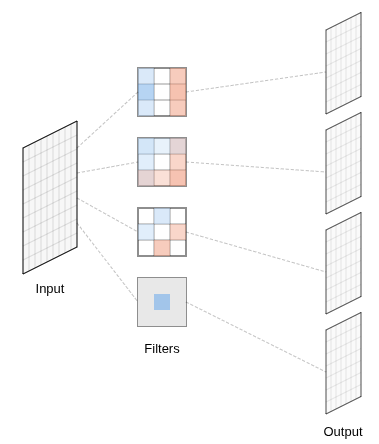
Convolutional Neural Networks
- CNN Architecture:
- Layers are small, learned filters
- Feature map per layer
- Apply ReLU to feature maps
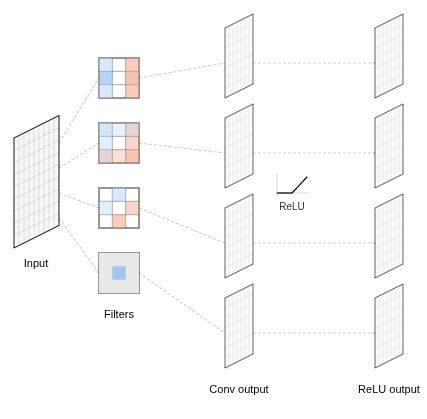
Convolutional Neural Networks
- CNN Architecture:
- Layers are small, learned filters
- Feature map per layer
- Apply ReLU to feature maps
- Stack Conv layers
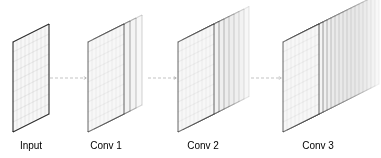
Pooling
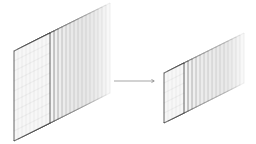
- Convolutional layers dramatically increase the size of outputs
- Max pooling layers reduce the spatial size
- Look at 2x2 or 3x3 grid and pick maximum value
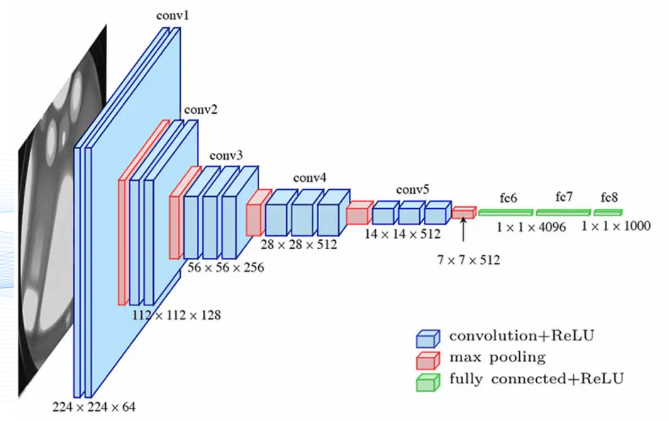
Full Architecture
- CNNs mix 1-3 Conv layers between max pooling layers
- Have some fully connected layers at the end for classification
CNNs Outperform Fully Connected for Images
Fully Connected:
Fully Connected:
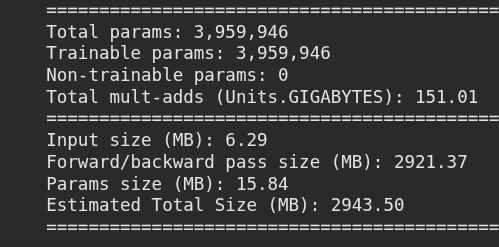
CNNs Outperform Fully Connected for Images
Fully Connected:
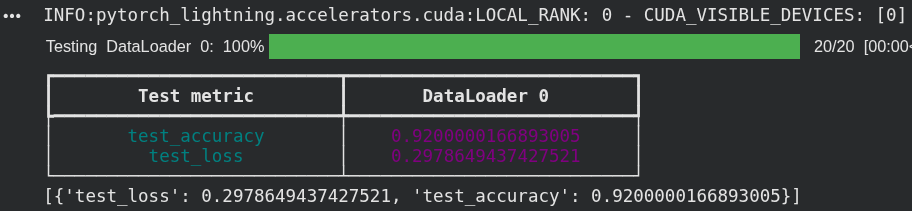
Fully Connected:
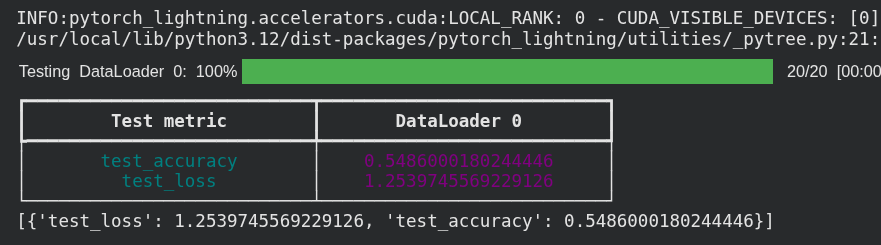
Data Augmentation
- Instead of modifying models, we modify training set with transformations!
- Data augmentation is one of the most powerful “tricks” out there
Deep Learning
- Over time, networks have become deeper
- Empirically, they lead to higher accuracy
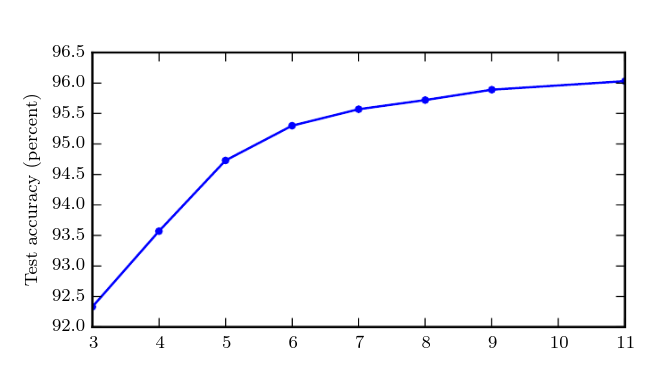
Goodfellow et al
Deep Learning
- Over time, networks have become deeper
- Empirically, they lead to higher accuracy
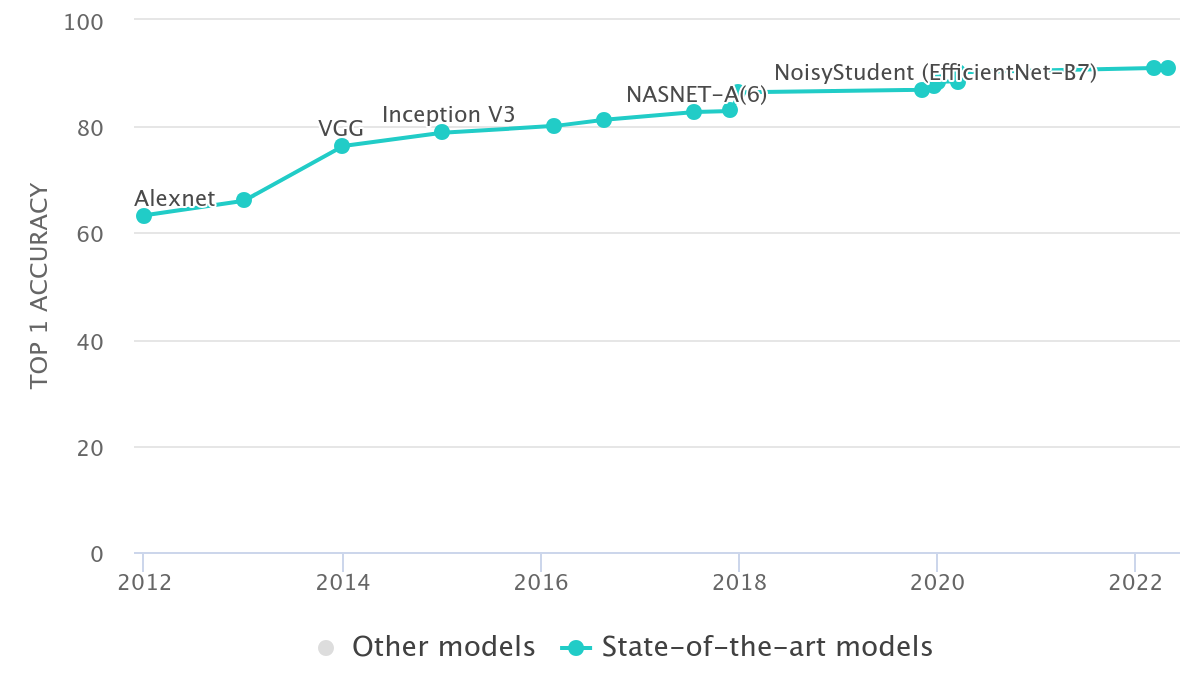
ImageNet Challenge
Different than more neurons
- Scaling up neurons often doesn’t help in shallow nets
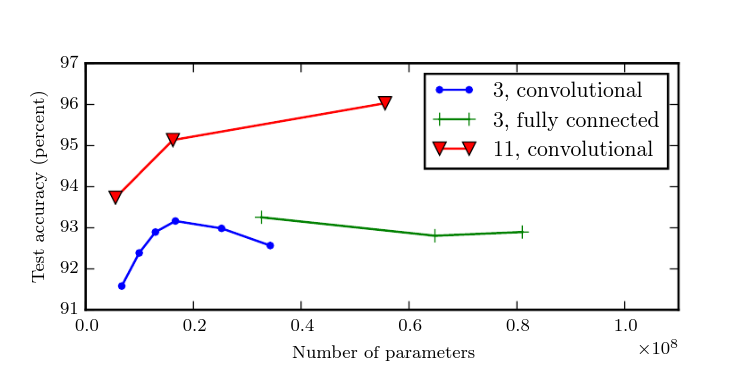
Goodfellow
Vashing Gradients
- Landscape of deep network varies by layer:
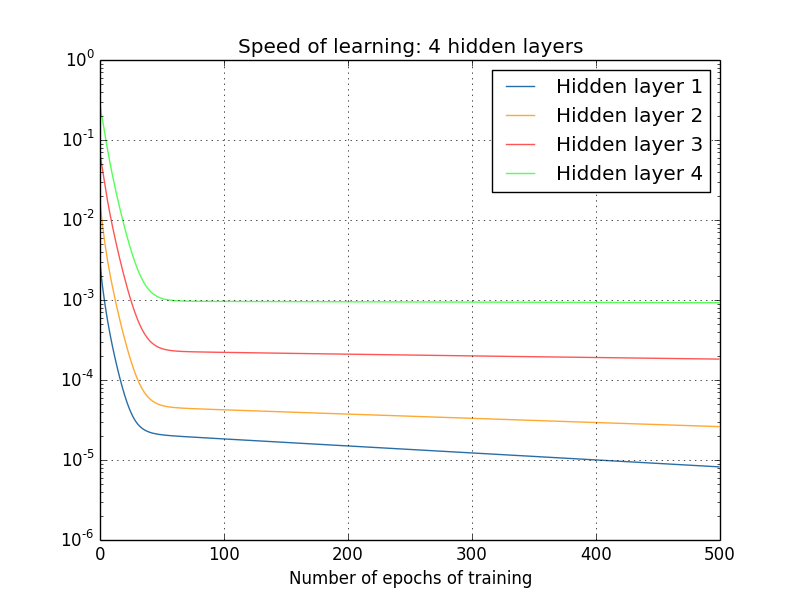
Nielson
Why Vanishing Gradients?
- Consider a deep network with one neuron per layer:
![]()
- If activation function is \(\phi\) can write it as: \[ f(x_1) = \phi \circ (w_n x + b_n) \circ \phi \circ (w_{n-1}x + b_{n-1}) \circ \\ \phi\circ \cdots\circ \phi \circ(w_1 x +b_1) (x_1) \]

Taking Derivatives
- The close to the output, the fewer “terms” in the derivative:
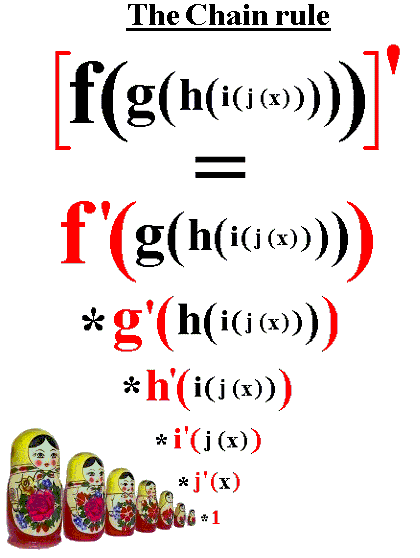
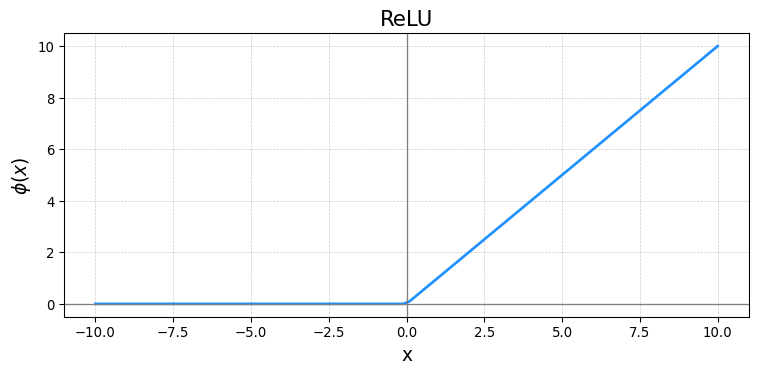
Solution: Activations
- Rectified Linear Unit (ReLU)
\[ \phi(x) = \cases{0& \text{if} \quad x\leq 0 \\ x& \text{if} \quad x>0} \]
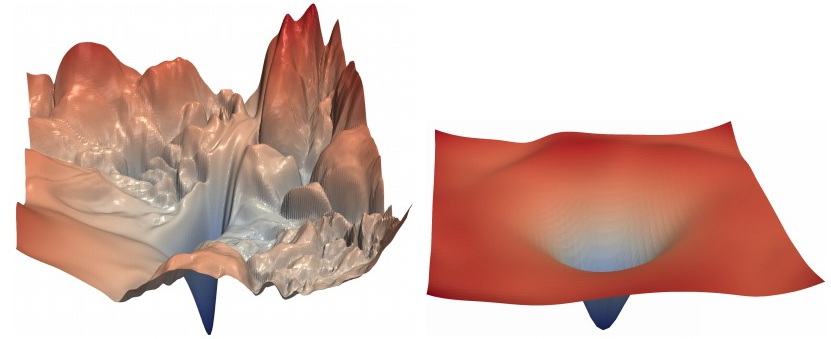
Spiky Loss Landscape
- Ideally, as you move in the direction of the gradient the loss smoothly decreases
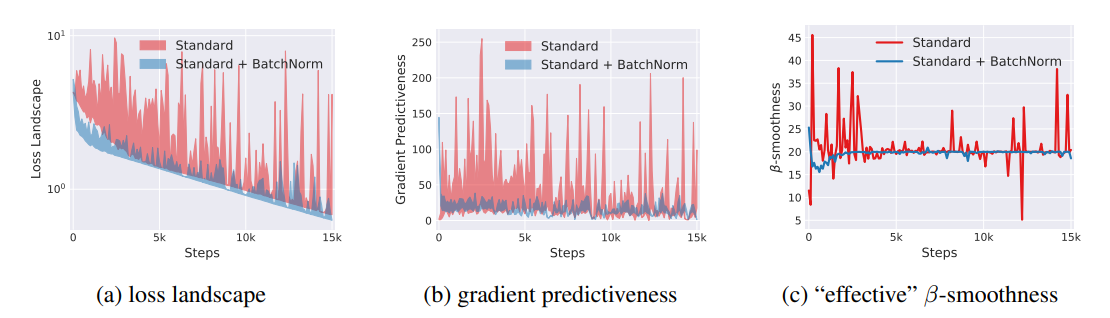
Batch Norm Enables Training Deep Networks
- Batch Norm makes the loss landscape much smoother
Thanks
![]()