DATA 622 Meetup 14: RNNs and Text
2026-05-04
nyhackr Thursday May 14th!

Sequential Data
- Data has a one-dimensional order:
ISLP
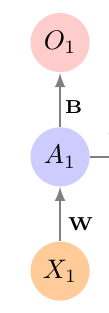
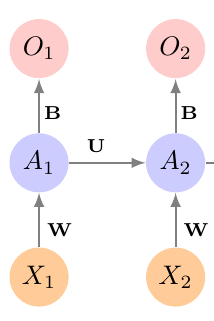
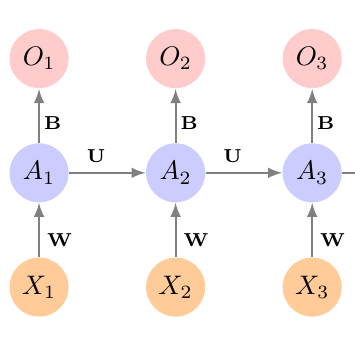
Recurrent Neural Networks
- Take advantage of the inductive bias:
- What comes next depends on what came before
Apply the network to the data sequentially
Apply it to the old activations and next state
Repeat
Use the final output for your prediction
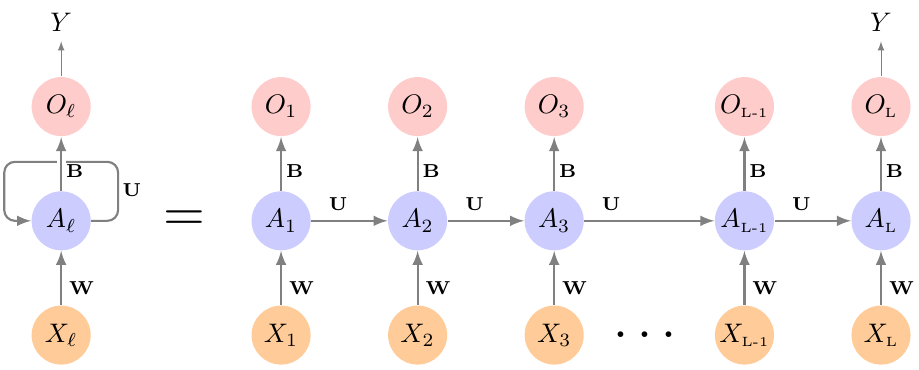
RNN Example: IMDB Sentiment
imdb.com
- IMDB contains millions of movie reviews
- Can we predict sentiment from text?
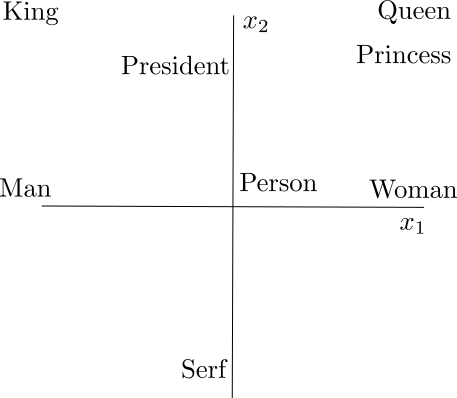
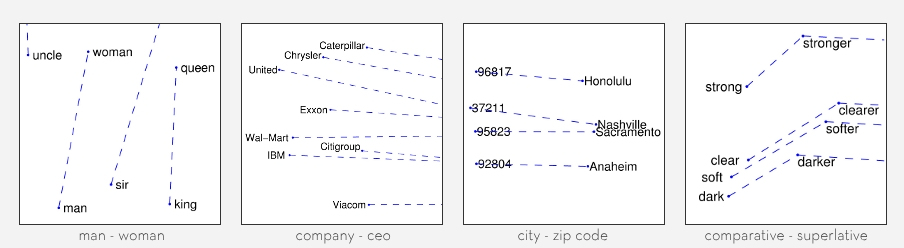
Similar Words Cluster Together
- Queen and Princess are near
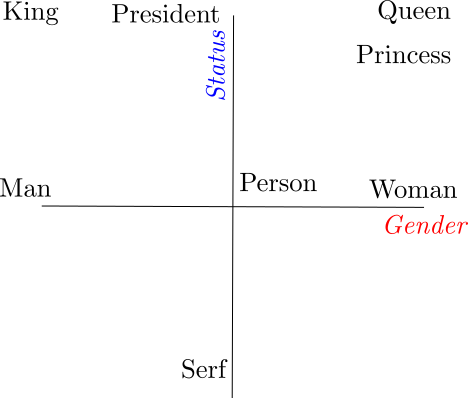
Features May Be Interpretable
- One axis is Gender, other is Status
Dimension Reduction
- Each word is now a vector in \(m\)-dimensional space
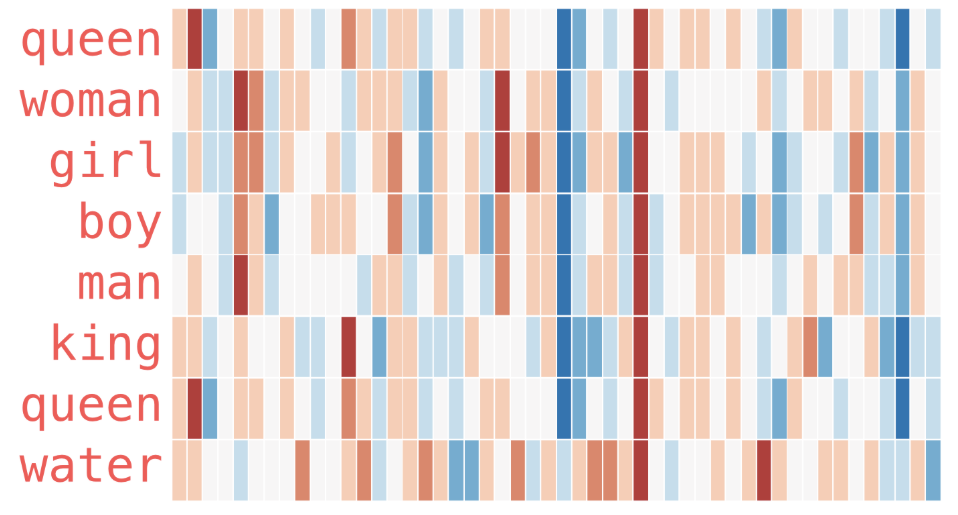
Jay Alammar
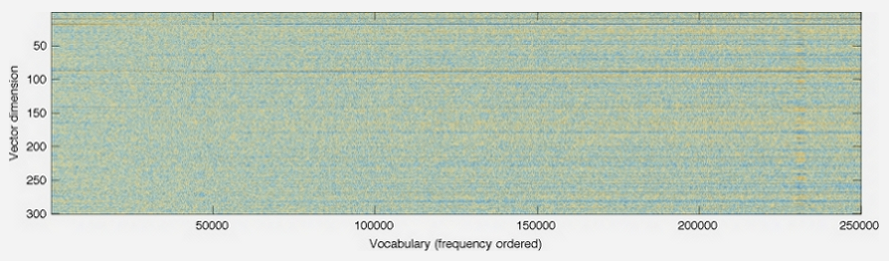
How to Embed?
- Pretrained Options
- Global Vectors for word representation (GloVe)
- Trained on wikipedia text, up to 300 dimensions:
How to Embed?
- Pretrained Options
- Global Vectors for word representation (GloVe)
- Trained on wikipedia text, up to 300 dimensions:
Vanishing Gradients in RNNs
- RNNs cause vanishing gradients
- ReLU can’t be used!
- Sequence length compounds it
- RNNs lose key information
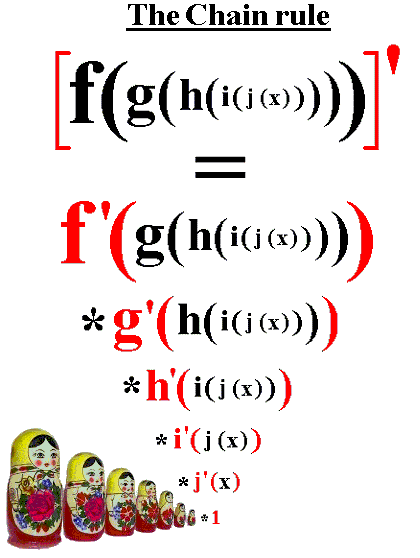
Forgetting
- Forgetting is number between 0 and 1
- Depends on \(h_{l-1}\) and \(X_l\)
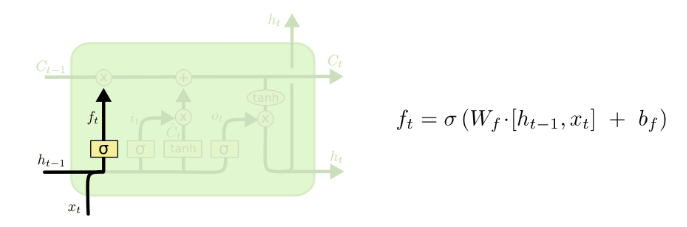
Christopher Olah
Input
- Input is number between 0 and 1
- Candidate state is new info to add
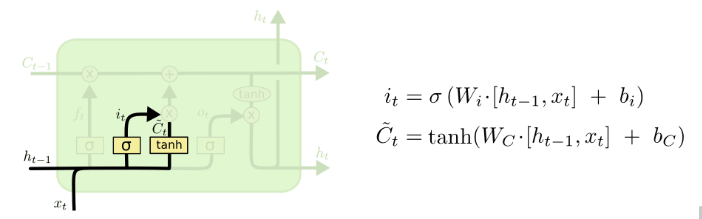
Christopher Olah
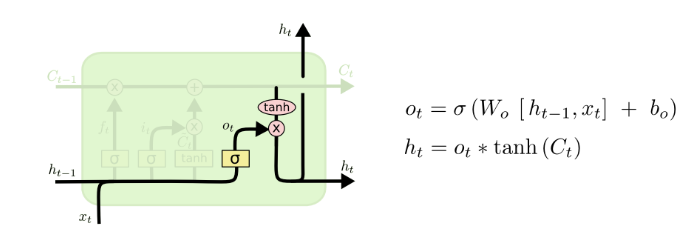
Cell State Update Diagram
- Ready for the update
Christopher Olah
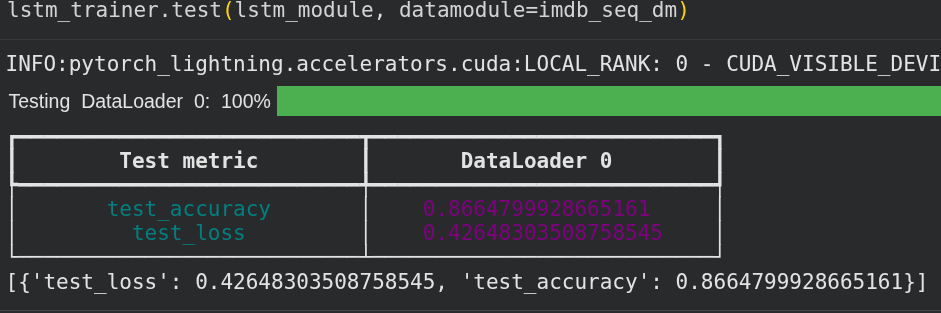
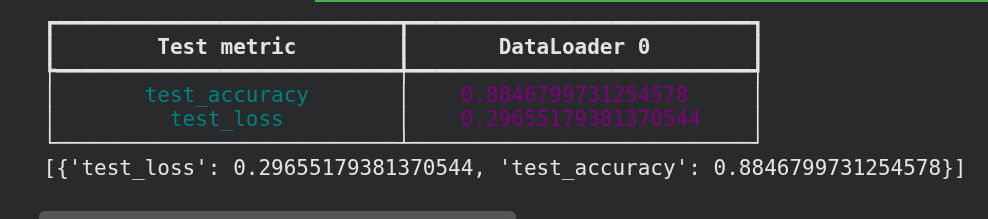
Get a small boost
Before tuning 86%
![]()
After tuning 88%
![]()
Thanks
![]()