DATA 622 Meetup 15: Pretrained Models
2026-05-11
nyhackr Thursday May 14th!

Lab Comments
- No ridge regression without using the standard scaler!!!
- Pick CausalML Hyperparameters to Make things Smooth
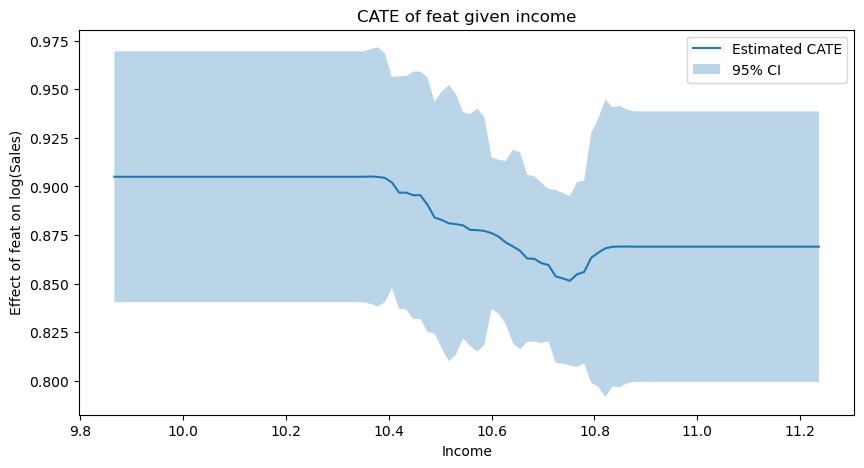
Lab Comments
- No ridge regression without using the standard scaler!!!
- Aggressive Choices Lead to Aggressive Fits
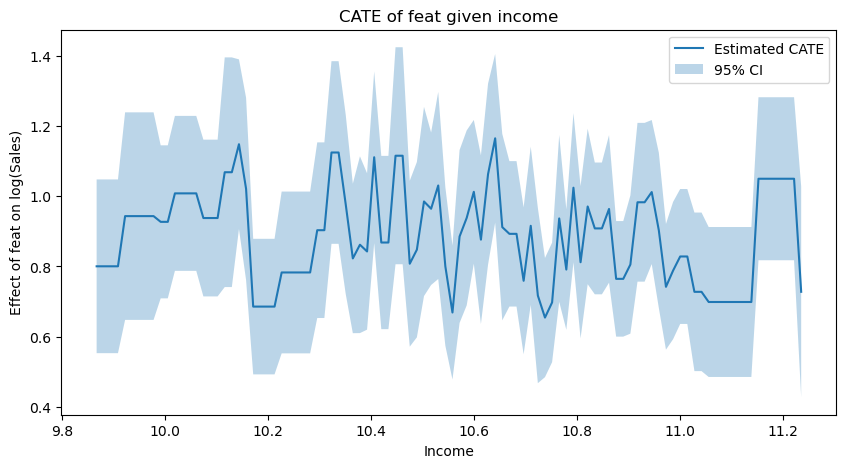
Contextual Meaning
- Consider an LSTM Processing this Text
Contextual Meaning
- Pronouns embedded as vectors, but mean specific things

Contextual Meaning
- LSTM incorporates their meaning via long-range states
Contextual Meaning
- Later, same pronouns may occur
Contextual Meaning
- LSTM’s understanding too compressed to remember previous context
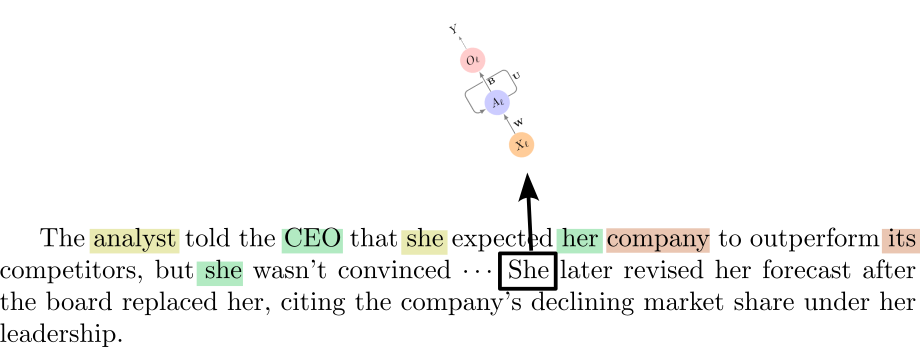
Context
- Distant words hold key context
Attention
- Consider simple sentence
Attention
- Each token has an embedding
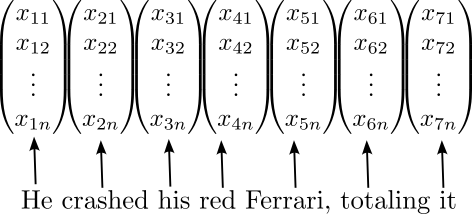
Attention
- Nearby tokens give context, change embedding in next layer

Attention
- Accumulate changes to embedding in next layer
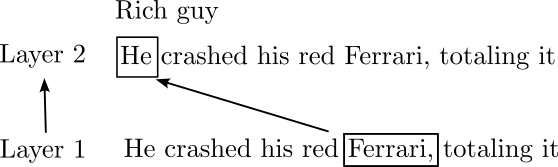
Attention
- Accumulate changes to embedding in next layer

Attention
- Accumulate changes to embedding in next layer

Transformer Achitecture
- A transformer is an architecture containing layers of transformer blocks.
Encoder Models: BERT
- 22 Transformer Layers
- 150M paramters
- Head is trained to predict masked words
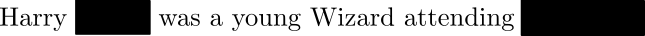
Encoder Models: BERT
- 22 Transformer Layers
- 150M paramters
- Head is trained to predict masked words
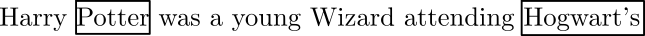
Fine Tuning Large Models
- LLMs start life as “Base Models”
- They just produce text:
LoRA Impact
Fine-Tuning leads to stunning performance improvements with relatively little effort
Original Model:
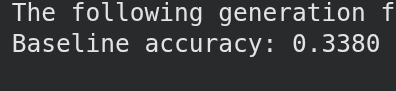
- Fine Tuned Model:

Thanks!
![]()