DATA 622 Meetup 7: Regularization
2026-03-09
Week Summary
- Presentations this week
- Work on projects with aim to get something working this month
- Perfect it in the final month
- Homework 4 Due Sunday
- Coding vignette on RidgeCV and Lasso
nyhackr Tomorrow at NYU!
![]()
nyhackr.org
Jiahao Chen on March 25th!
![]()
https://us02web.zoom.us/meeting/register/pDyeuQ9ERrqYbBNKJPBMkw
Regularization
- Method for optimizing the bias variance tradeoff
- Modify learning algorithm by adding a “penalty” to coefficients
\[
\mathrm{argmin}_{\mathbf{w}} \sum_{i=1}^n \log(p(y_i|\mathbf{x}_i,\mathbf{w}_i)) + \alpha f(\mathbf{w})
\]
- Use “hyperparameter optimization” in a cross-validation loop to find best penalty
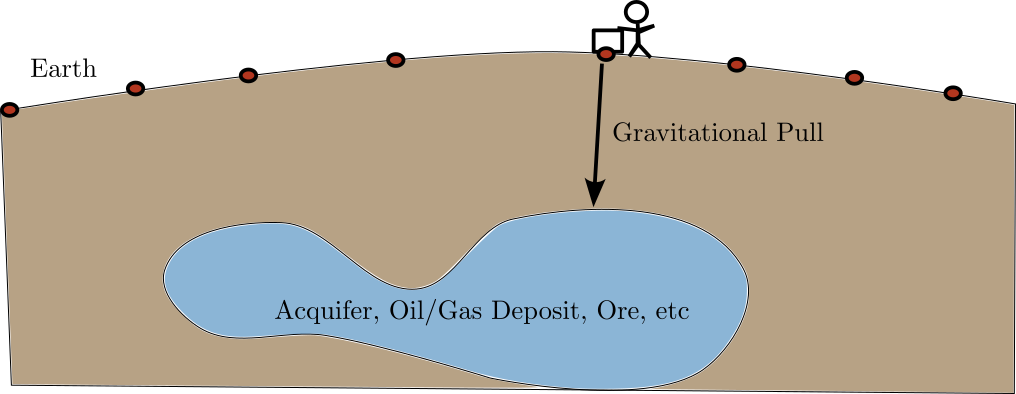
Motivation: What is Underneath the Surface?
- Goal: Find out what is underneat the Earth’s Surface
- Water, Oil, Gas, Minerals, etc
- Digging is expensive
- Measure subtle differences in gravity instead
![]()
What is Underneath the Surface
- Each material has different density, so exerts different gravitational force
- Can create linear regression problem to determine local density:
\[
\mathbf{g} \sim A\mathbf{\rho} + \epsilon
\]
What is Underneath the Surface
- Real Problem: Find ore in a 4\(\mathrm{km}^2\) by \(300\)m deep zone
- 443 surface gravity measurements \(\mathrm{g}\)
- 60,000 subsurface “blocks” \(\mathbf{\rho}\)
\[
\mathbf{g} \sim A\mathbf{\rho} + \epsilon
\]
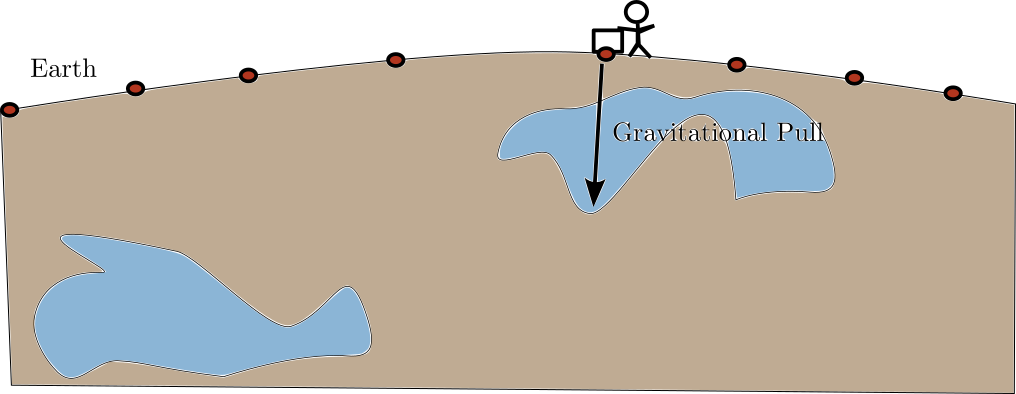
What is the problem?
What is Underneath the Surface
- Problem: Measurements are 2D, but target density is 3D
- Many more coefficients in \(\mathbf{\rho}\) than data \(\mathbf{g}\)
- Means there are many possible solutions with 0 error!
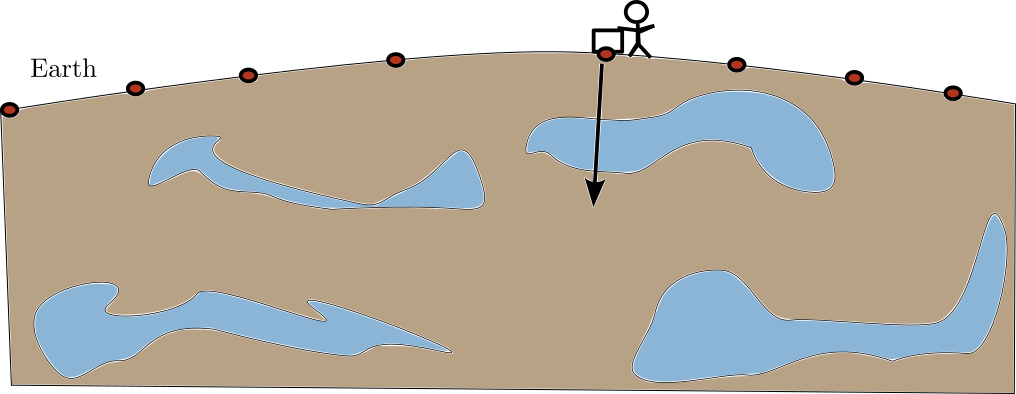
What is Underneath the Surface
![]()
What is Underneath the Surface
![]()
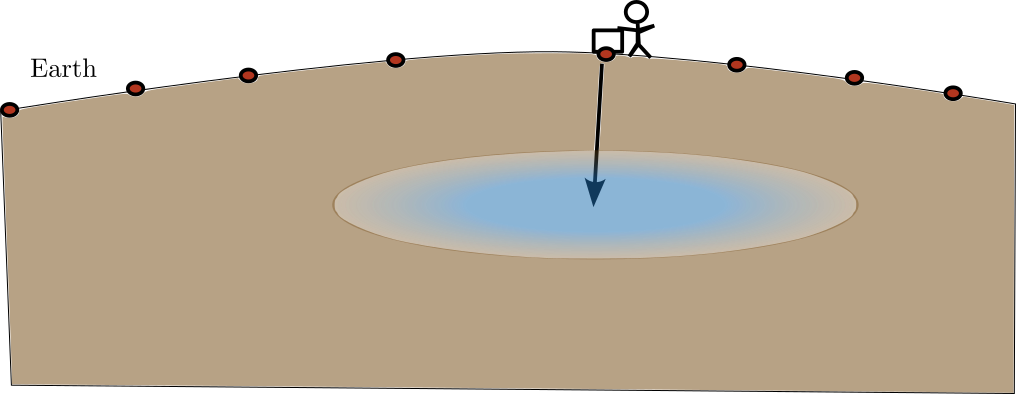
Solution: Force the coefficients to be smooth
![]()
Ridge Regression
- Ridge regression adds a penalty proportional to squared sum of coefficients
\[
\mathrm{argmin}_{\mathbf{w}} \sum_{i=1}^n (y_i -\mathbf{w}\cdot\mathbf{x}_i )^2 + \alpha \sum_{j=1}^p w_j^2
\]
- Effect is to “shrink” coefficients towards \(0\)
- Don’t do this with intercept
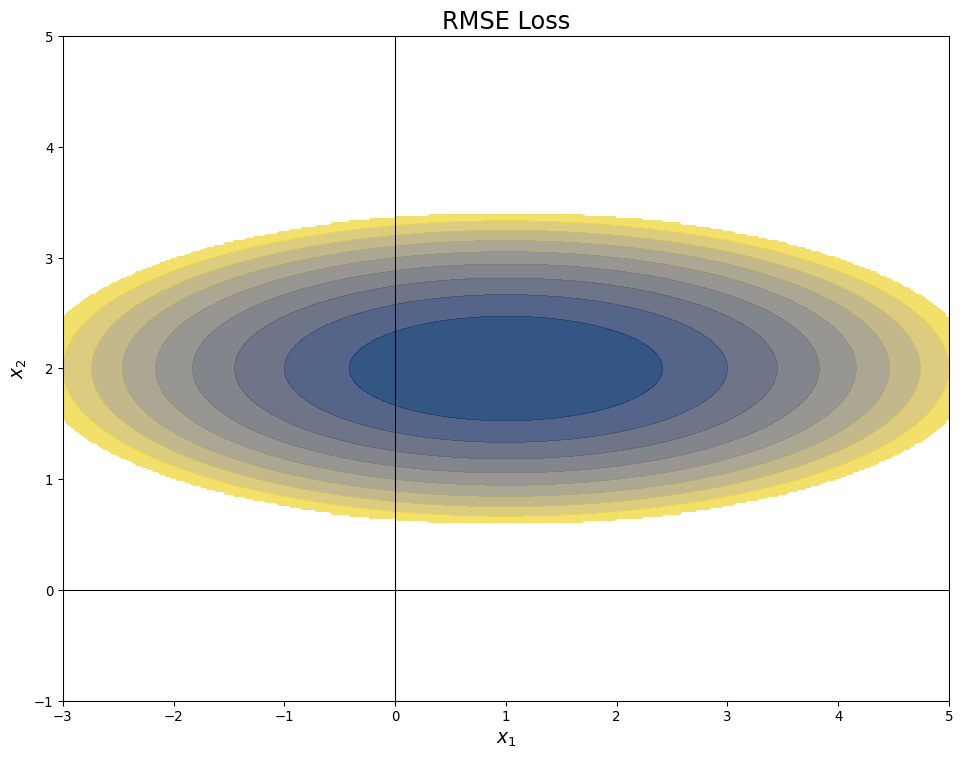
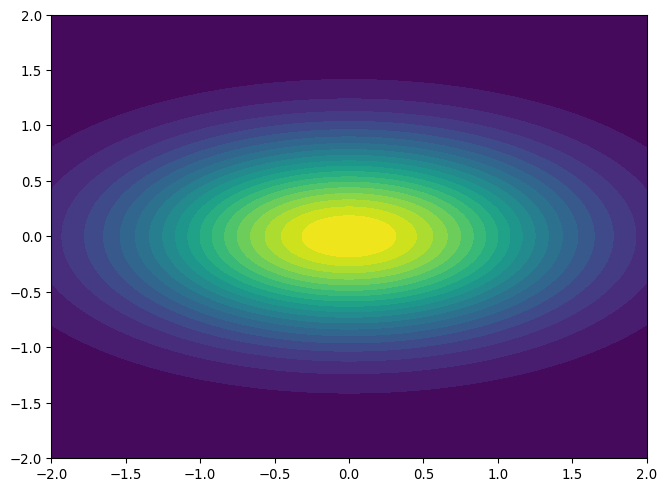
Ridge Regression Picture
- Consider two variable linear regression
- Error function contours are ellipses:
![]()
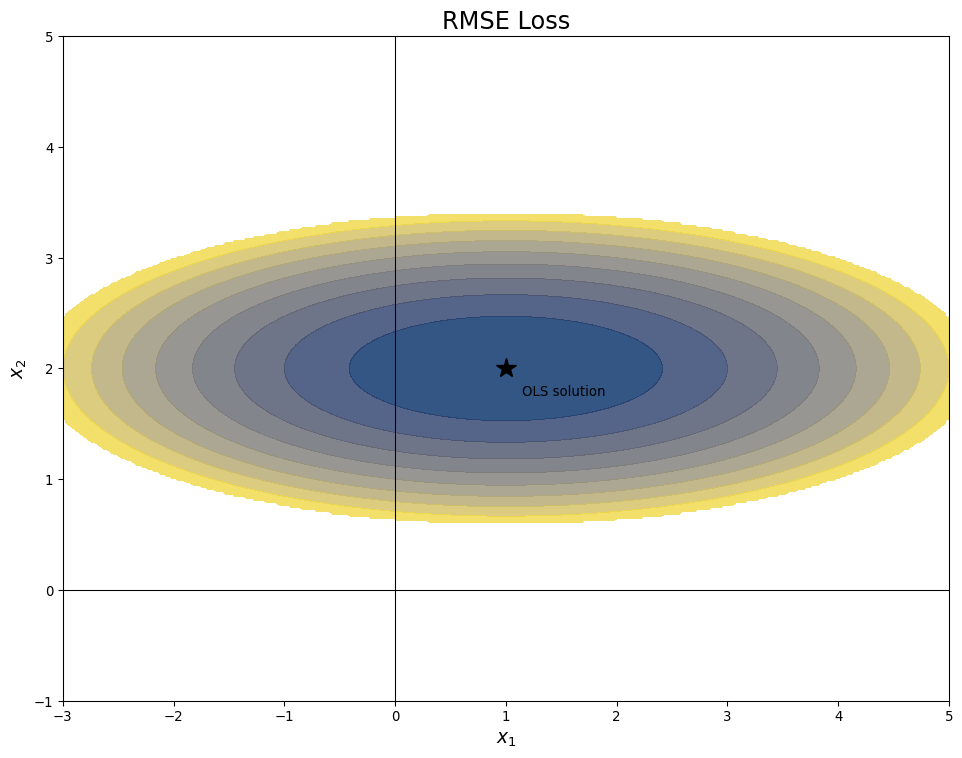
Ridge Regression Picture
- Consider two variable linear regression
- Lowest error at center of ellipse
![]()
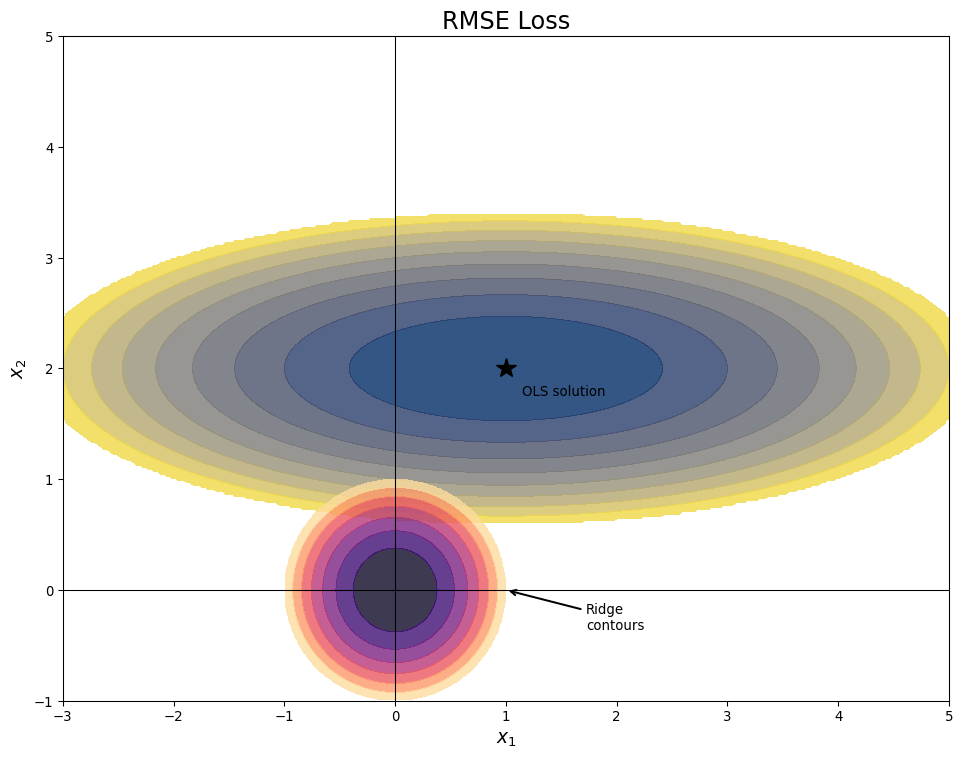
Ridge Regression Penalty
- Consider two variable linear regression
- Penalty increases in circles away from origin
![]()
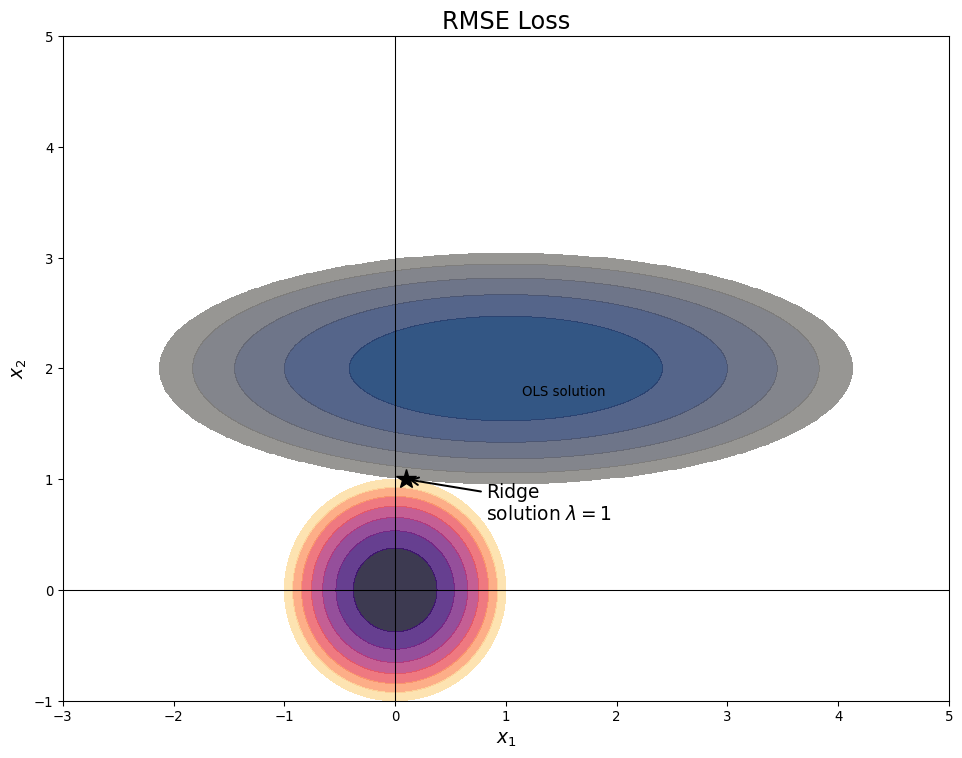
Ridge Regression Penalty
- Consider two variable linear regression
- Ridge Solution balances penalty and RMSE
![]()
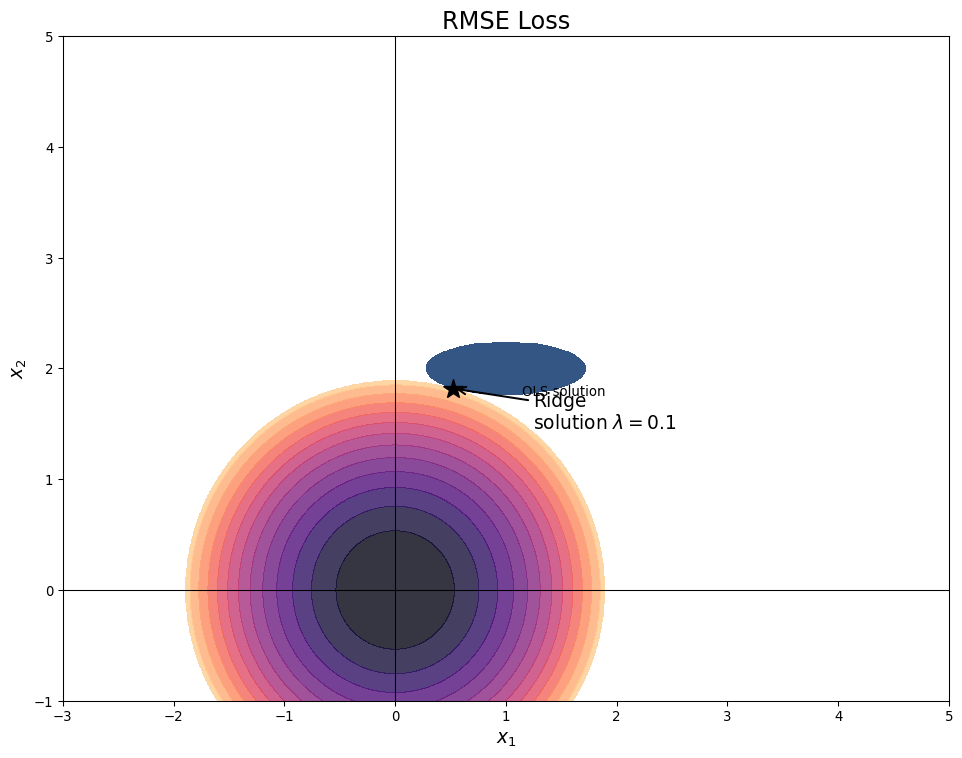
Ridge Regression hyperparameters
- Varying \(\lambda\) changes balance
- Small \(\lambda\) mimics OLS
![]()
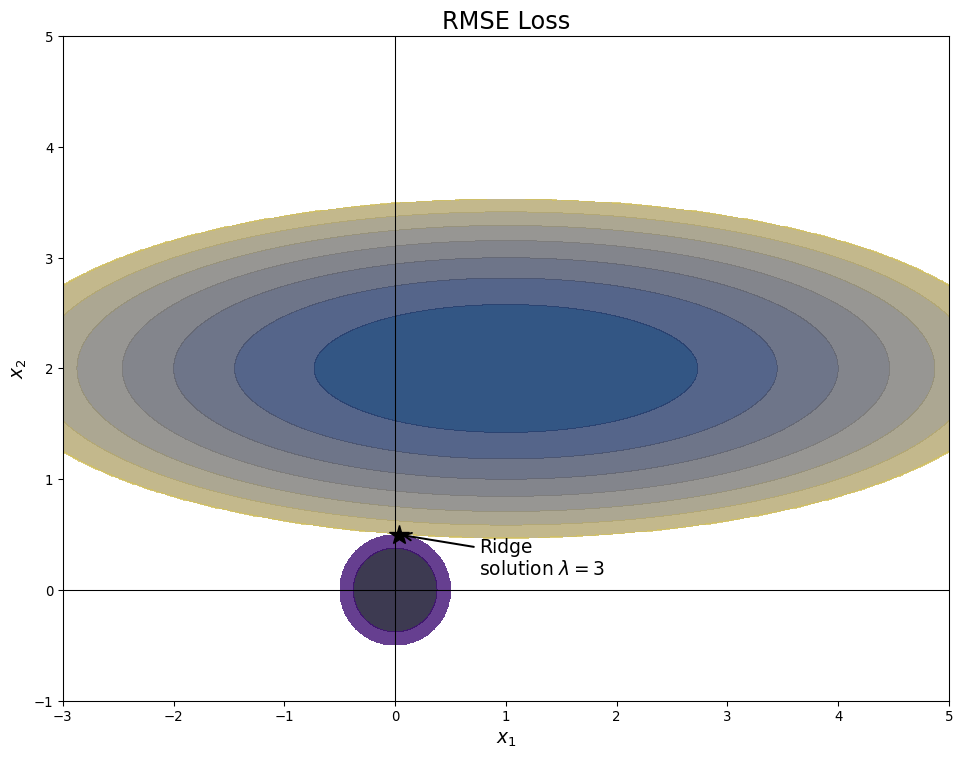
Ridge Regression hyperparameters
- Varying \(\lambda\) changes balance
- Large \(\lambda\) shrinks coefficients
![]()
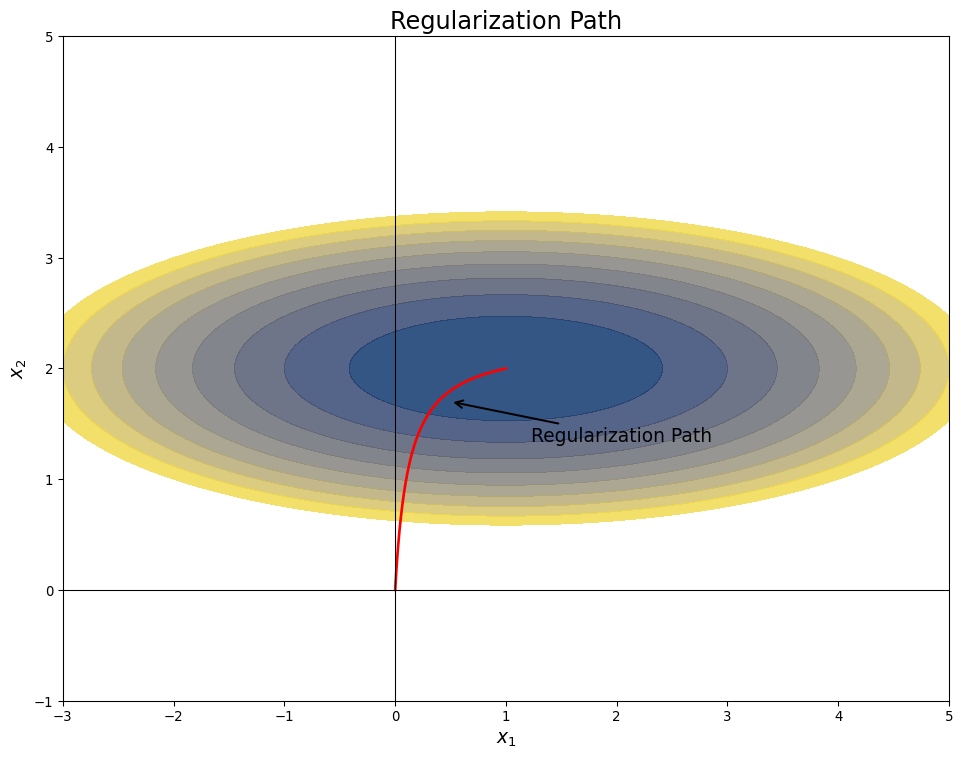
Regularization Path
- Increase \(\lambda\) from \(0\) to \(\infty\)
- Solution moves from OLS to 0
![]()
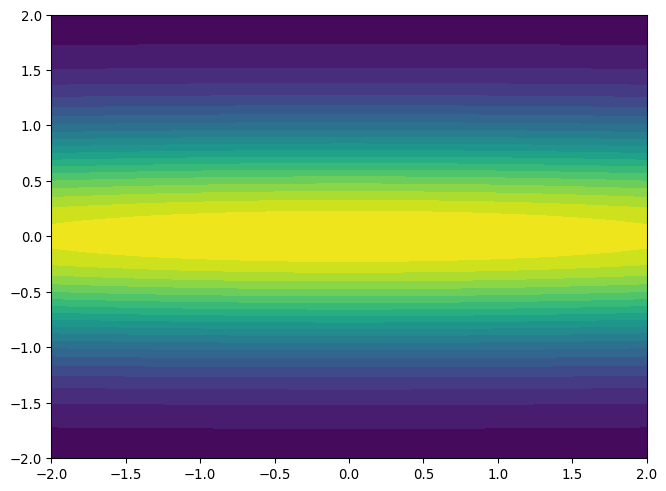
Ridge Regression
- Consider objective function with a “ridge”
- Flat direction represents irrelevant feature
![]()
Ridge Regression
- Name comes from geometry
- Regularizer turns ridge to peak
![]()
Bayesian Linear Regression
\[
\mathbf{y} \sim \mathrm{Normal}\left(X\theta,\sigma^2 I\right) \\
\mathbf{\theta} \sim \mathrm{Normal}\left(0, \frac{1}{\lambda} I\right)
\]
- \(\frac{1}{\lambda}\) is variance of prior distribution on \(\theta\)
- \(p(\theta|X)\) is normal
- \(E(\theta|X)\) is least squares ridge regression solution
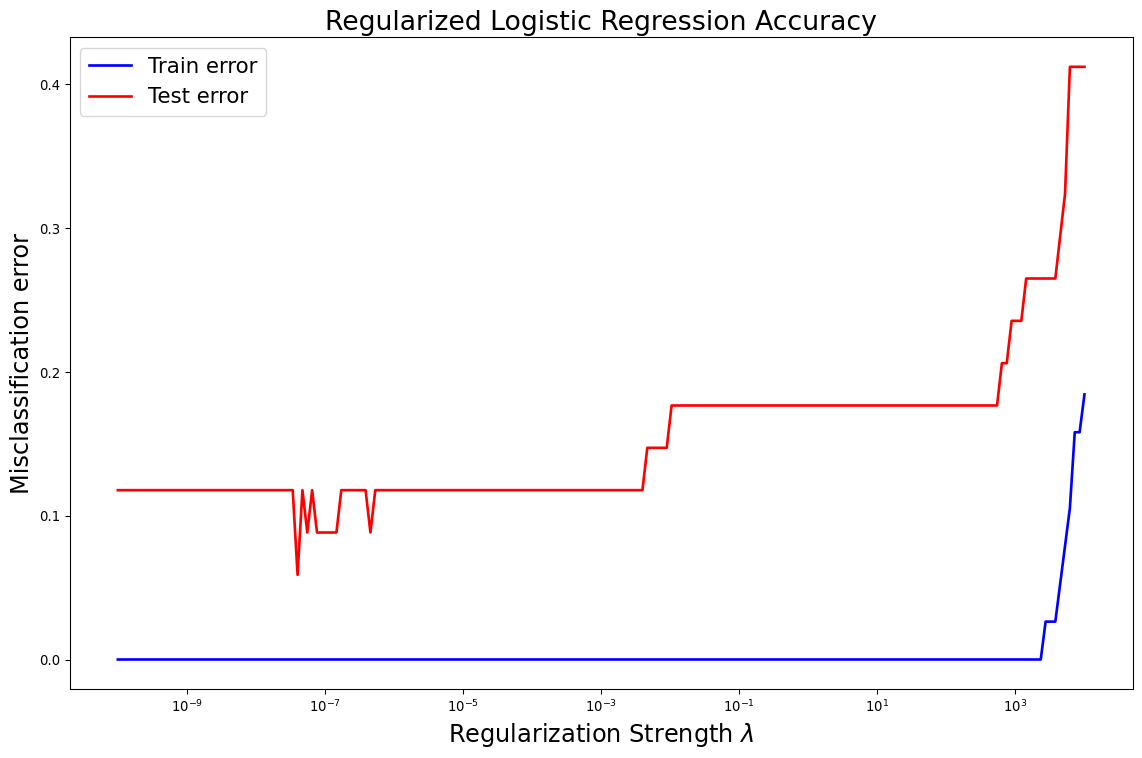
Ridge Regression for AML/ALL
- Consider the Leukemia Data from Meetup 5
- 7000+ features, 72 patients
![]()
Ridge Regression for AML/ALL
- Consider the Leukemia Data from Meetup 5
- 7000+ features, 72 patients
![]()
Hyperparameter Optimization
- The process of varying the strength of the regularization and comparing the test error is called hyperparameter optimization
- \(\lambda\) is a hyperparameter
- Not fit like a traditional model coefficient
- Impacts performance of model
- Pick hyperparameters like you select models
- We will meet many hyperparameters in the rest of this course
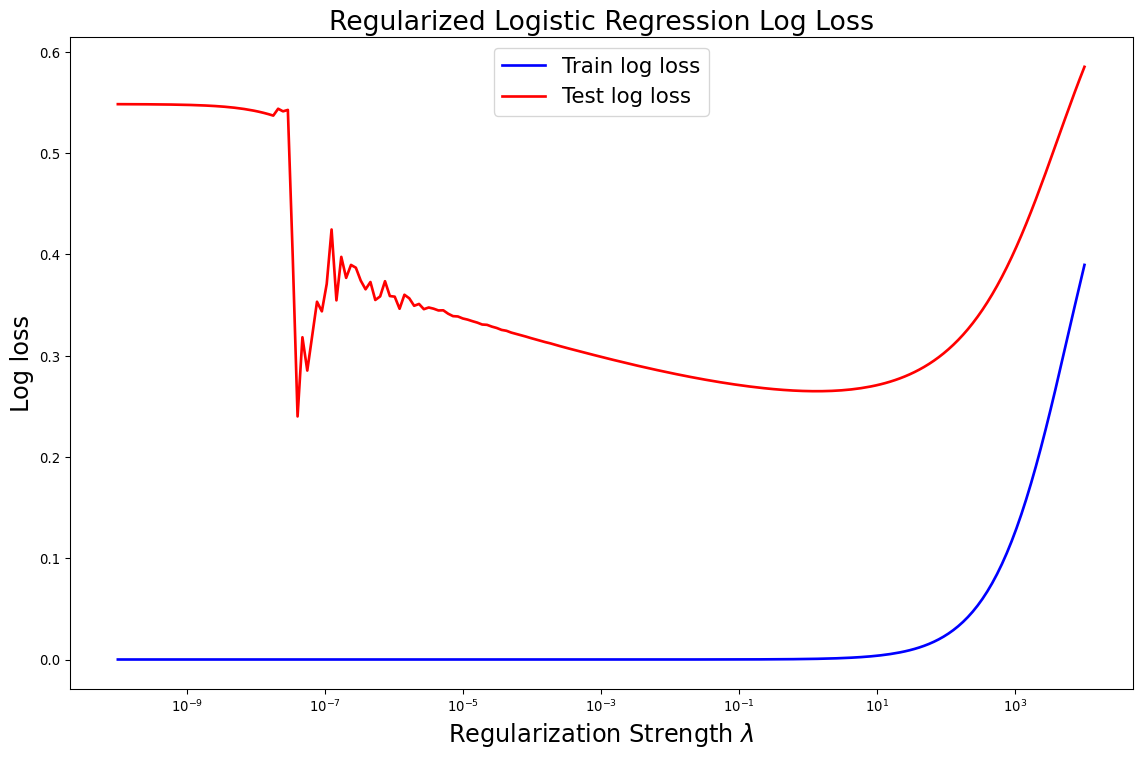
Can do Better With Cross-Validation
- Typical to find best \(\lambda\) using cross-validation
- Also more efficient with data
![]()
Can do Better With Cross-Validation
- Typical to find best \(\lambda\) using cross-validation
- Also more efficient with data
![]()
Ridge Regression Considerations
- Must scale predictors first
- Otherwise you are effectively putting arbitrarily different priors on each coefficient
- For example, if you have population and age as predictors:
- Population ranges to millions
- age is under 100
- Penalty will constrain shrink age coefficient more than population
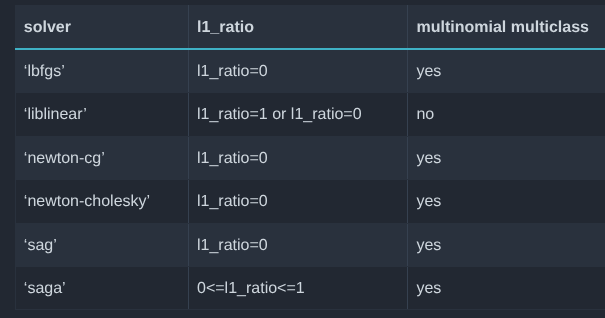
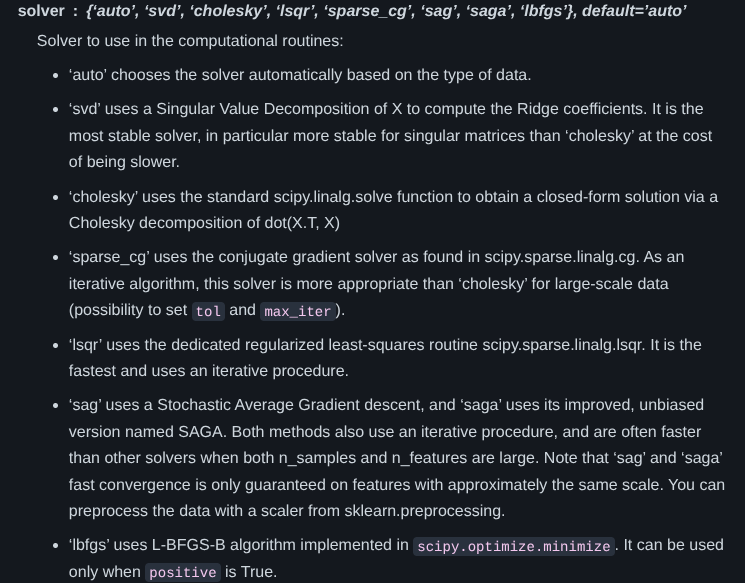
Ridge Regression Considerations
- There are many solver options:
![]()
‘sklearn’ website
- It helps to know some linear algebra
Ridge Regression Considerations
- There are many solver options:
![]()
‘sklearn’ website
Ridge Regression Considerations
- There are many solver options:
- Each solver has a case where it is best
- ‘svd’, ‘cholesky’ most likely to get right answer, but slower than competitors
- ‘sparse-cg’ good for large, sparse problems
- ‘lsqr’ and ‘lbfgs’ fast iterative solvers, can tune accuracy
- ‘sag’ poor accuracy but for very large problems
The Lasso
- A regularization that uses a different penalty
\[
\mathrm{argmin}_{\mathbf{w}} \sum_{i=1}^n (y_i -\mathbf{w}\cdot\mathbf{x}_i )^2 + \alpha \sum_{j=1}^p |w_j|
\]
The Lasso
- A regularization that uses a different penalty
\[
\mathrm{argmin}_{\mathbf{w}} \sum_{i=1}^n (y_i -\mathbf{w}\cdot\mathbf{x}_i )^2 + \alpha \|\mathbf{w}\|_1
\]
- Also called \(L_1\) penalty
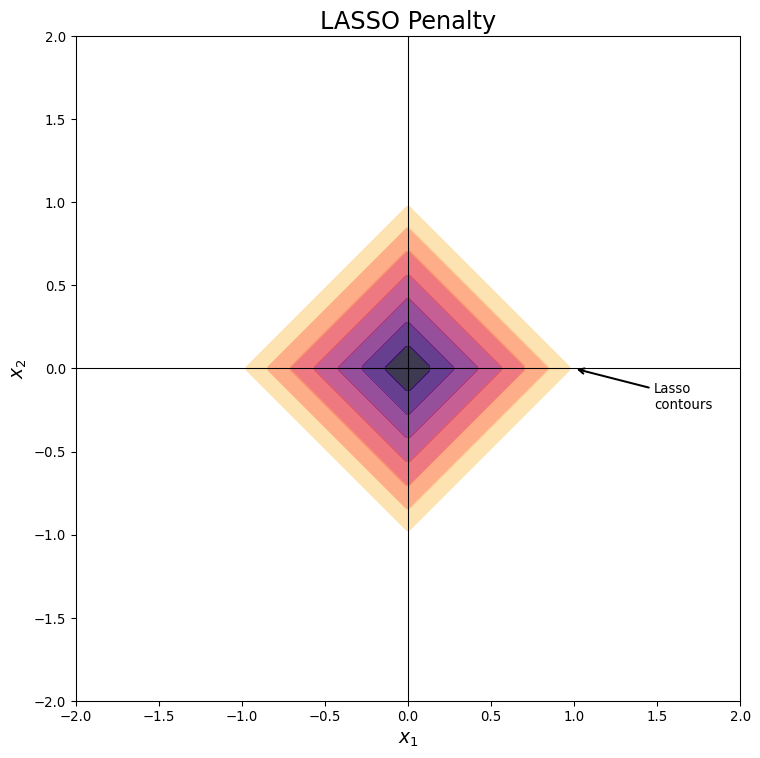
Lasso Geometry
- Unit “Circle” in Lasso is actually a square
- Coefficient values trade off directly
![]()
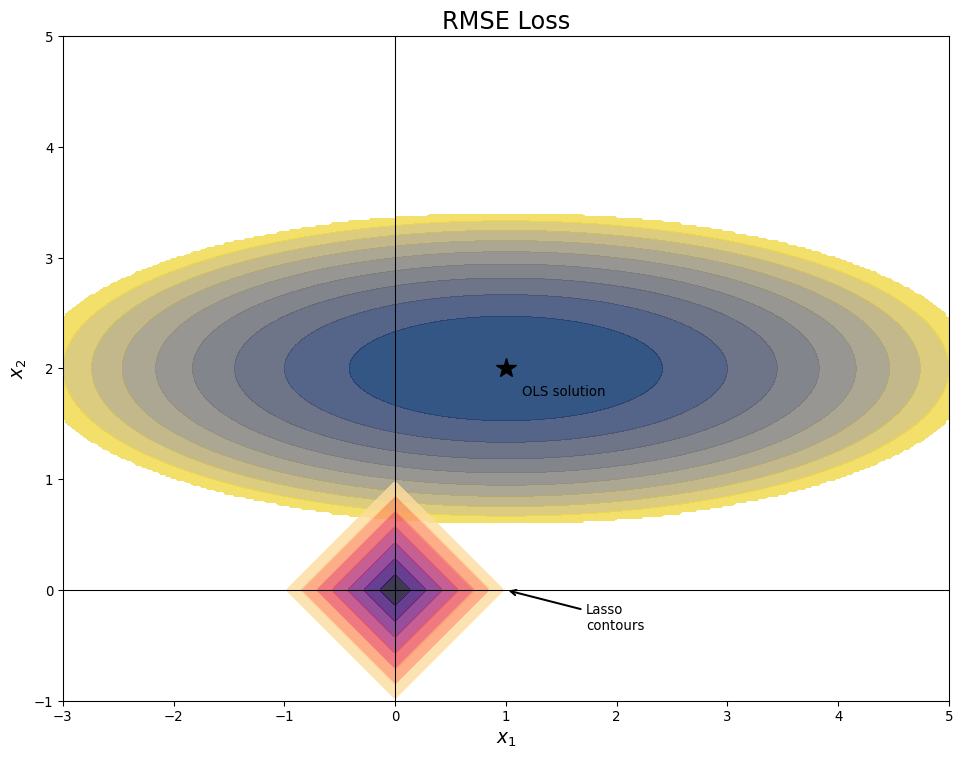
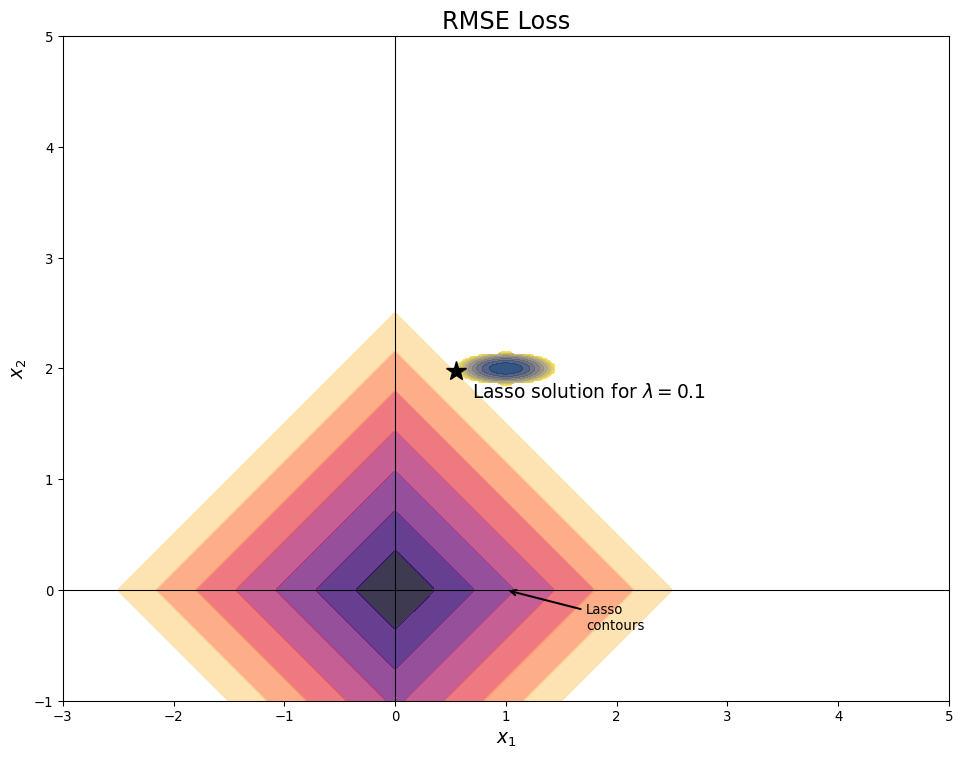
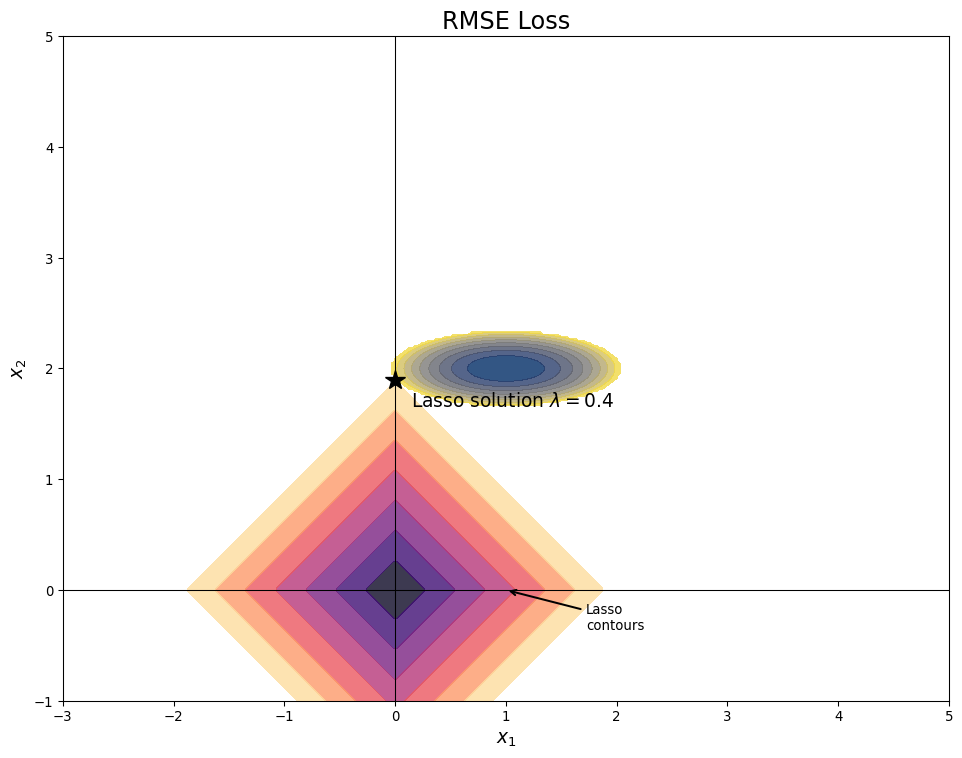
Lasso Causes Sparsity
- Sparse means that most values (here coefficients) are 0
![]()
Lasso Causes Sparsity
- Sparse means that most values (here coefficients) are 0
![]()
Lasso Causes Sparsity
- Sparse means that most values (here coefficients) are 0
![]()
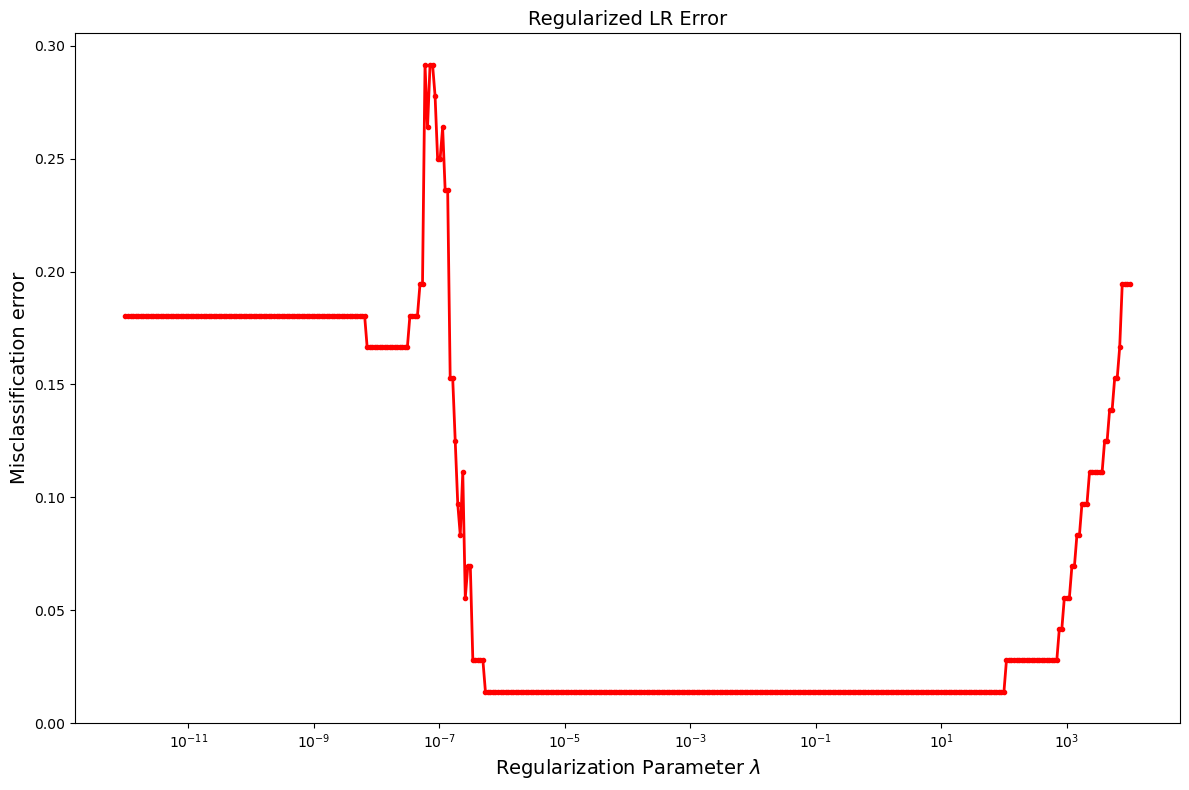
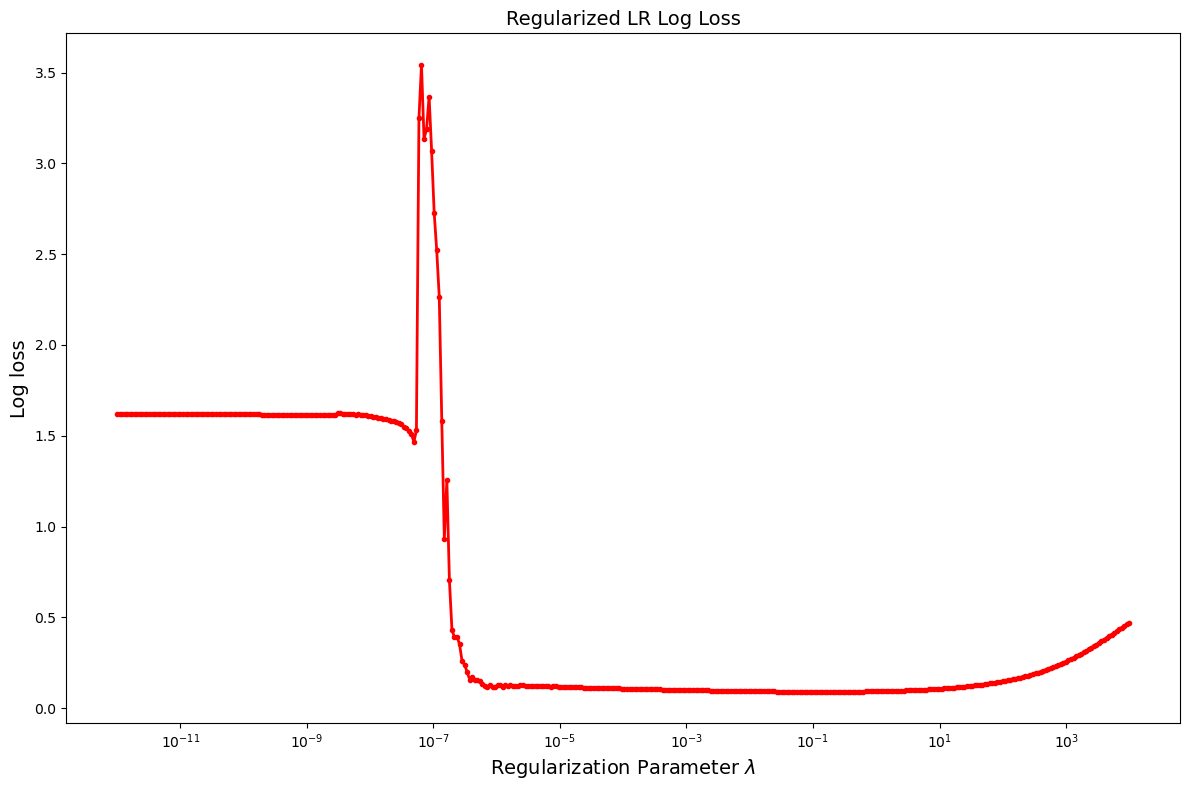
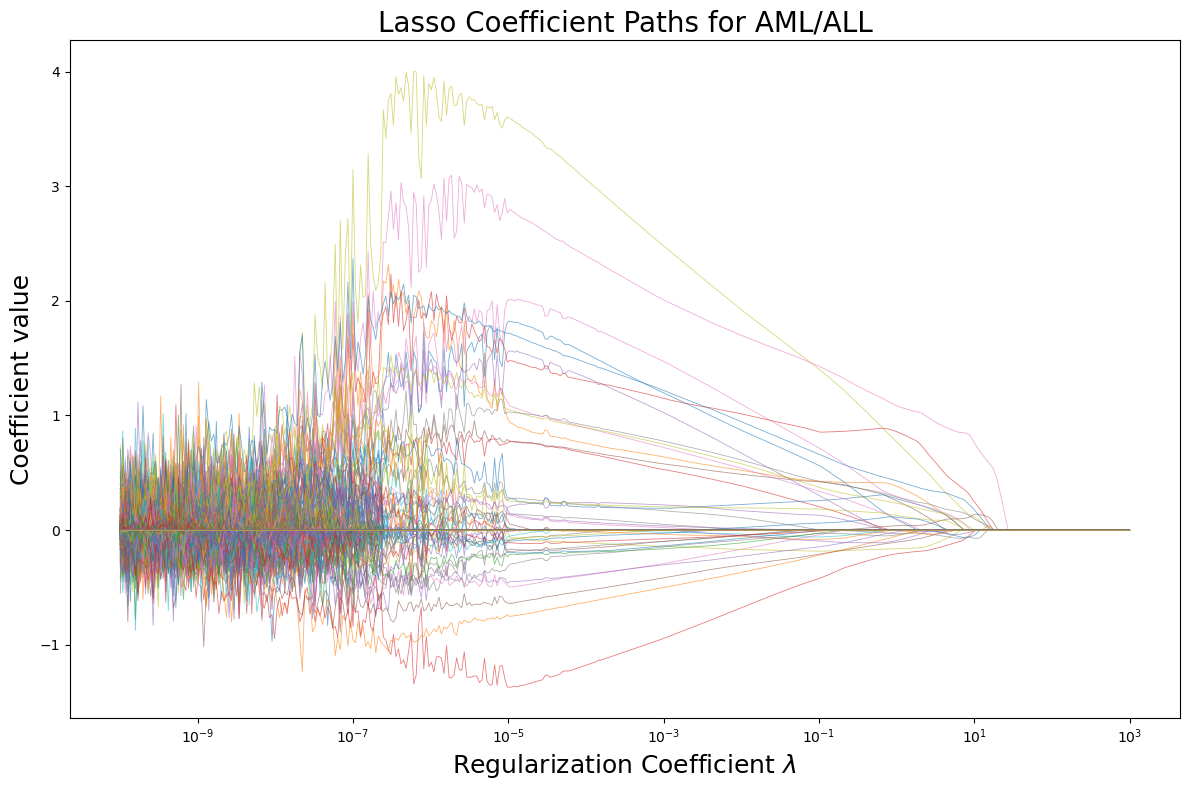
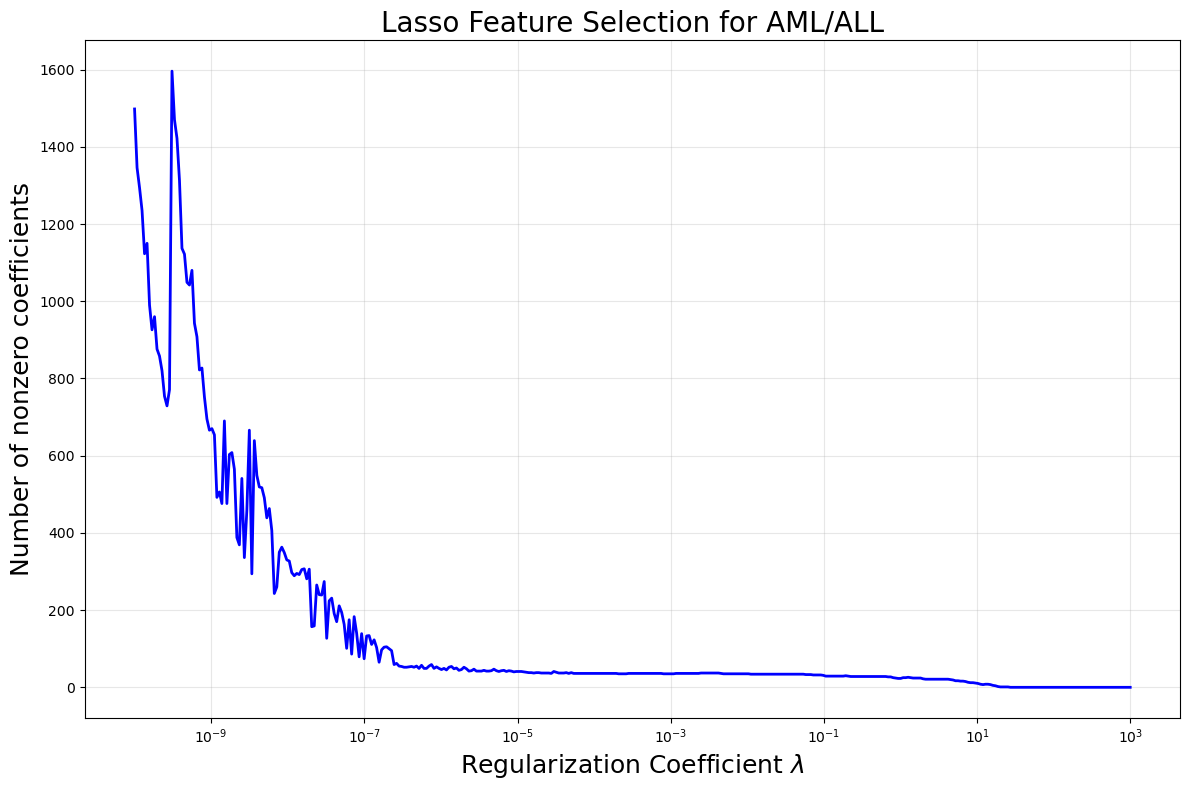
Lasso Pros
- Lasso Can be Viewed as a means of variable selection
- See here Lasso applied to AML/ALL problem
![]()
Lasso Pros
- Lasso Can be Viewed as a means of variable selection
- See here Lasso applied to AML/ALL problem
![]()
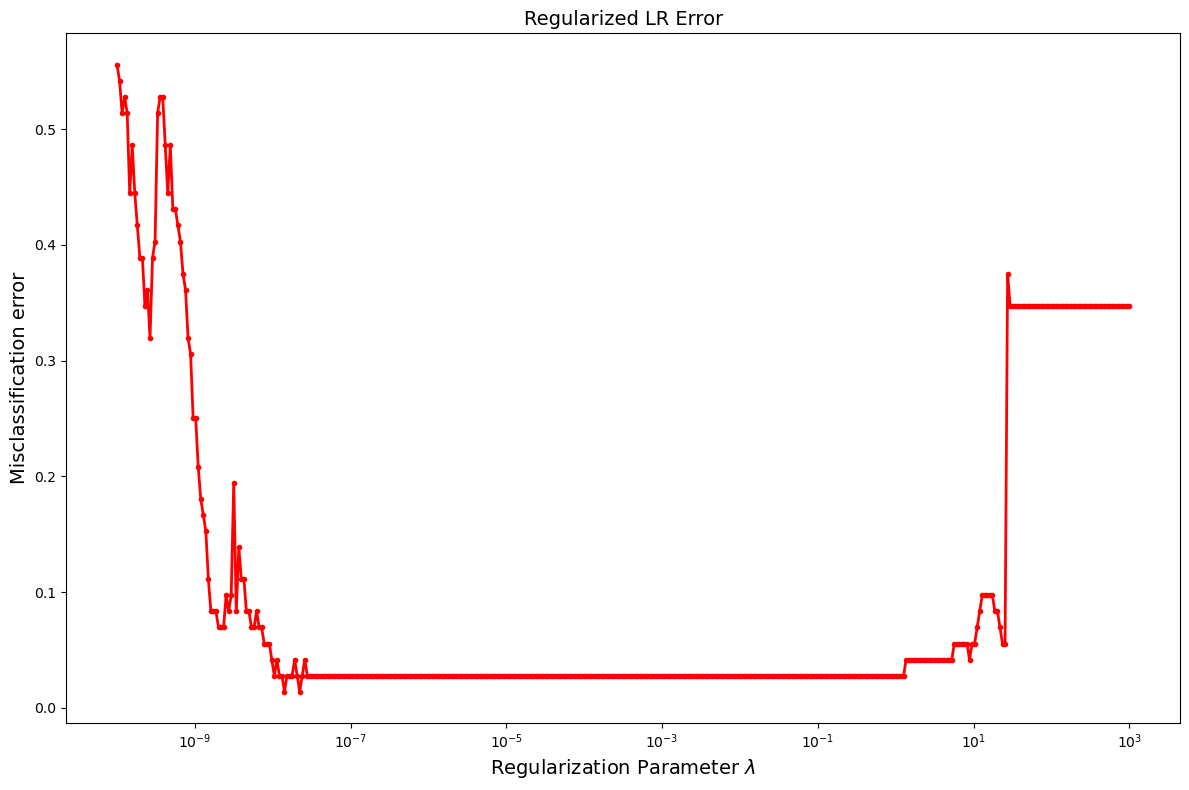
Lasso Pros
- Sparsity doesn’t trade off much if at all on performance
![]()
Lasso Pros
- Sparsity doesn’t trade off much if at all on performance
![]()
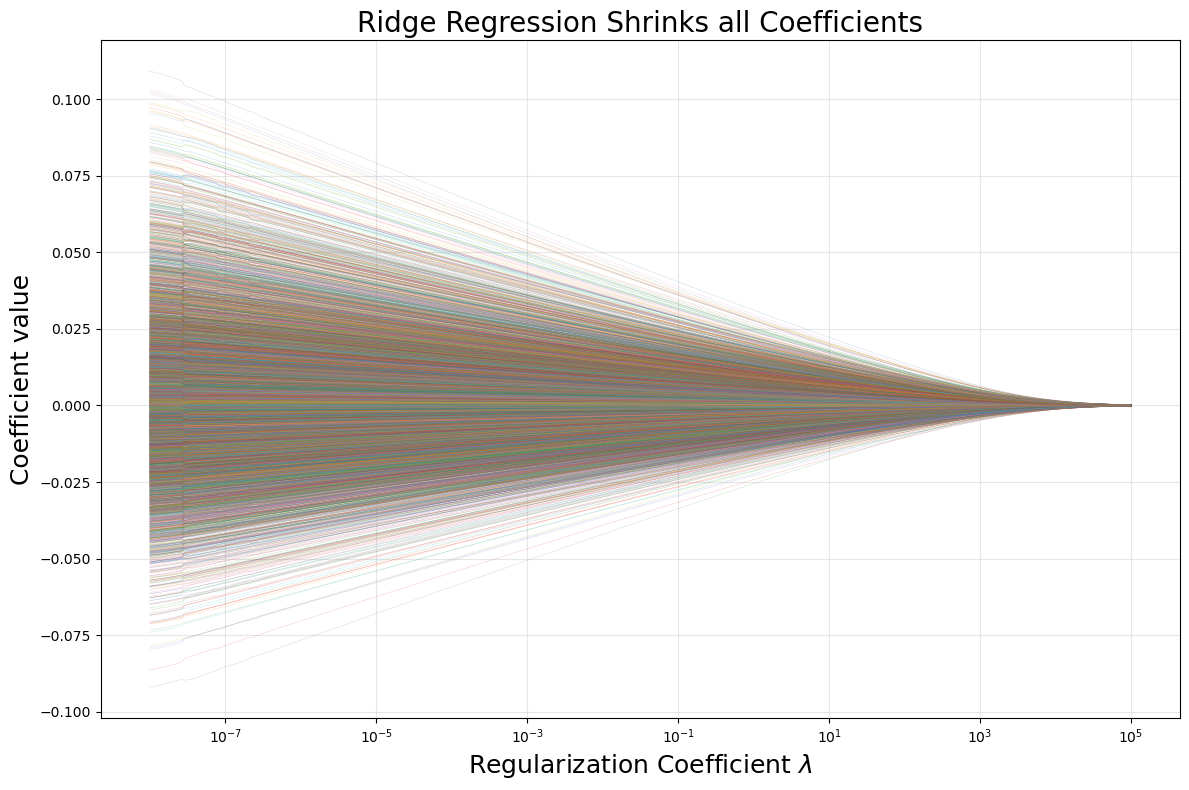
Lasso vs Ridge
- Ridge Regression smoothly shrinks all coefficients
![]()
Lasso vs Ridge Trade-Offs
- Lasso is more unstable (different coefficients for different cv folds/regularization parameters)
- Correlated features: Lasso might pick randomly whereas Ridge will keep all
- Ridge is usually faster and sometimes much faster
- Lasso also has a Bayesian Prior interpretation (Laplace/Double Exponential Priors)
Elastic Net
- Elastic Net Combines Both Penalties
\[
\mathrm{argmin}_{\mathbf{w}} \sum_{i=1}^n (y_i -\mathbf{w}\cdot\mathbf{x}_i )^2 + \lambda_1 \|\mathbf{w}\|_2^2 + \lambda_2 \|\mathbf{w}\|_1
\]
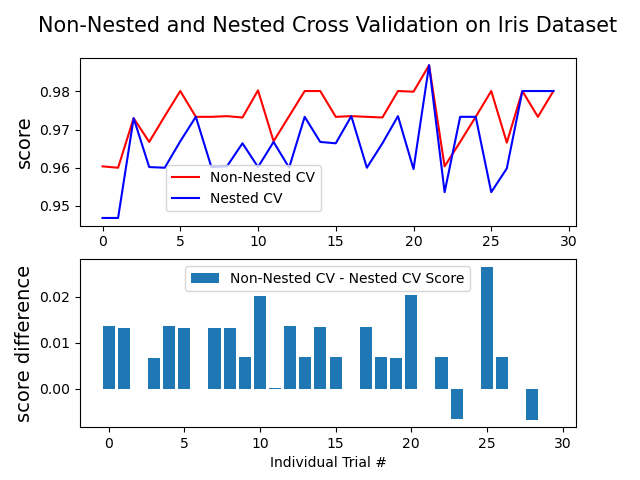
Nested CV and Hyperparameters
- The more hyperparameters the more careful you need to be with cross-validation
- Typical approach: Use CV to pick best hyperparameters and estimate out of sample accuracy
- Leads to overfitting because uses testing data to pick hyperparameter
Nested CV and Hyperparameters
- Nested Cross-Validation: Outer CV loop for testing
- For each fold, inner CV for hyperparameters
- Test that model on the outer fold
![]()
‘sklearn’ website
When to consider nested?
- When data is low
- When you have many hyperparameters
- When you are selecting between different models each with hyperparameters