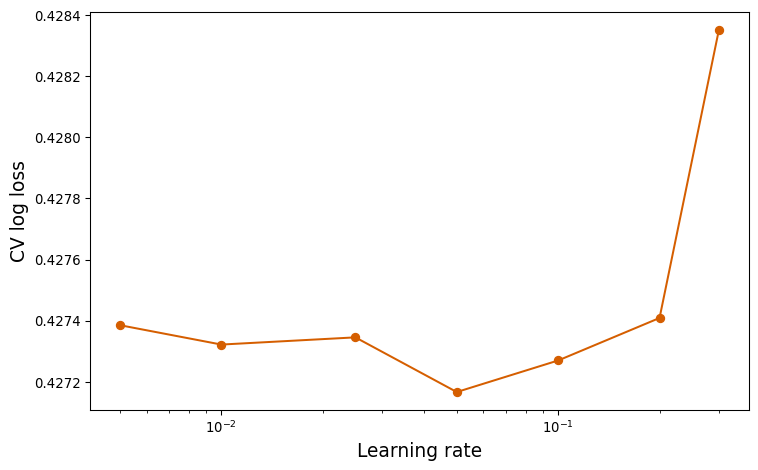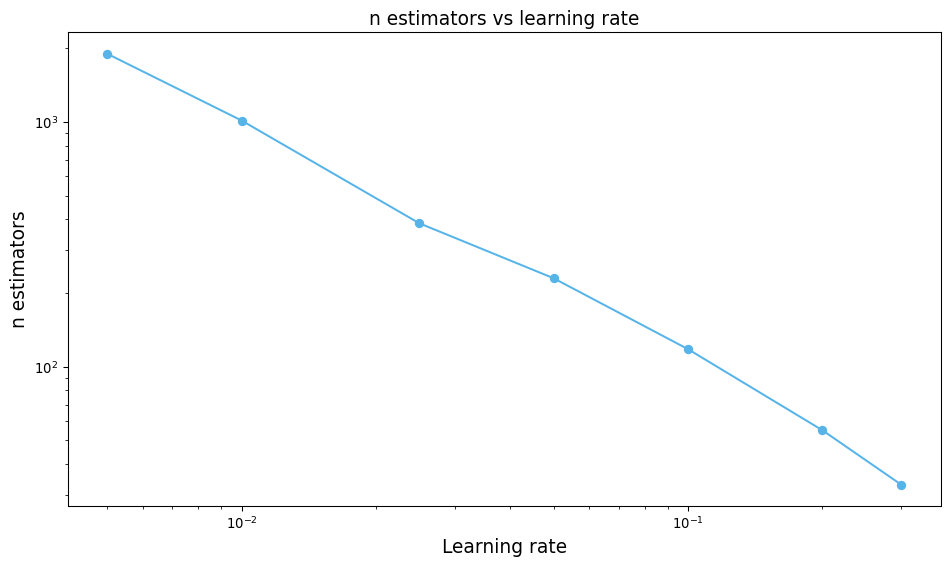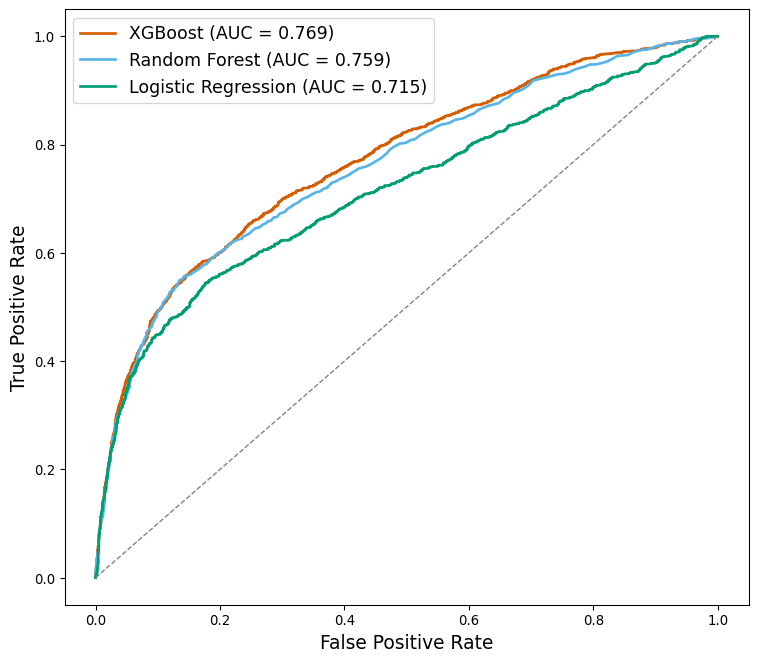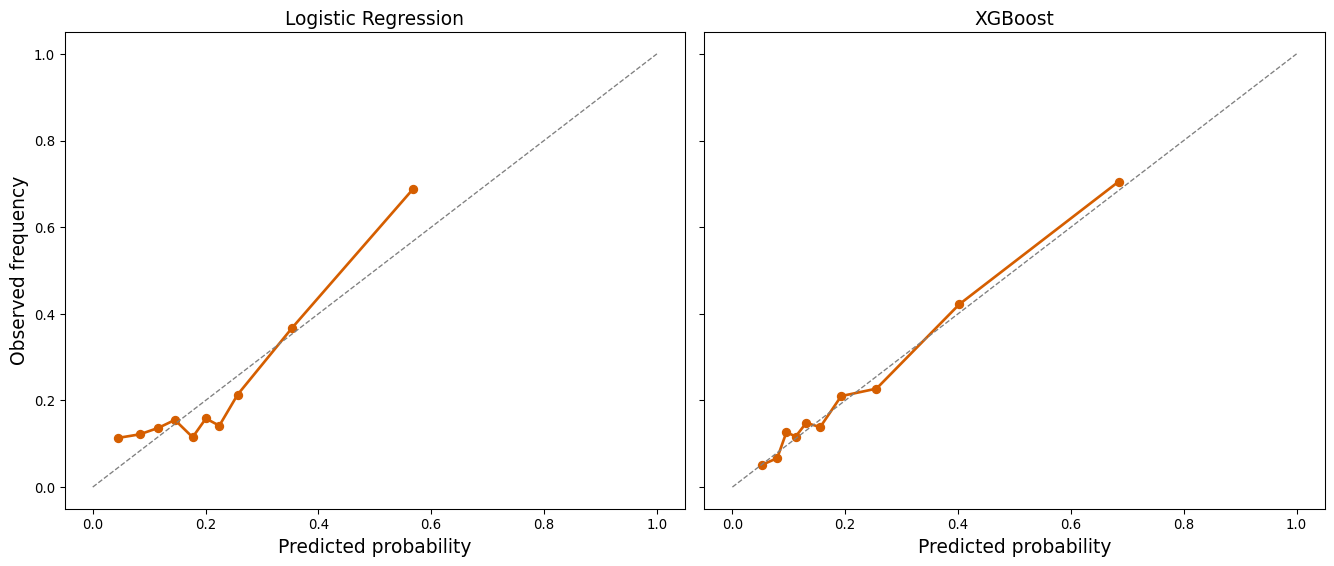



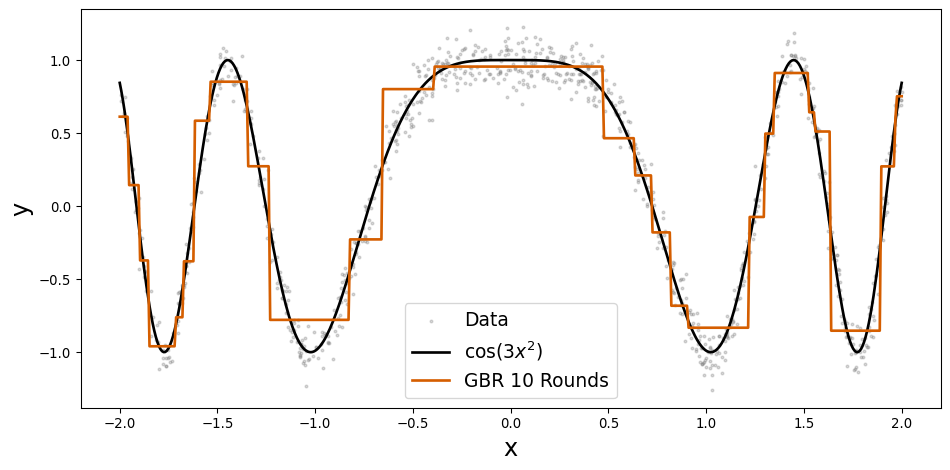
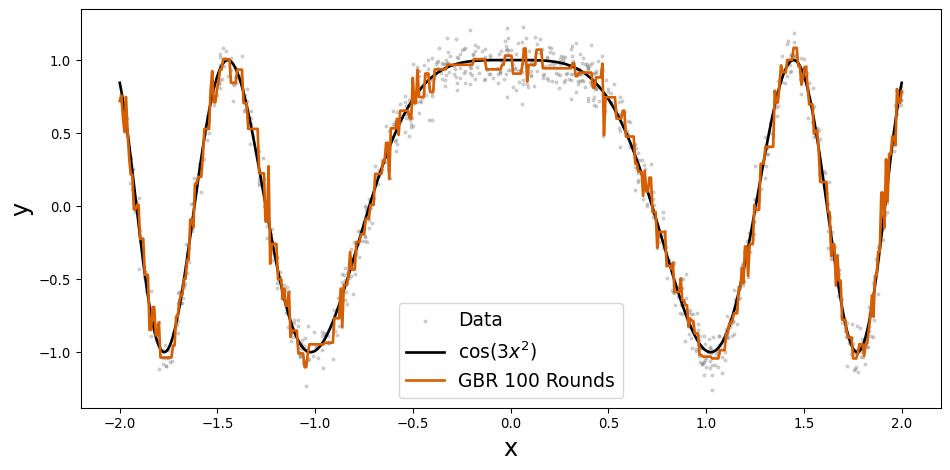
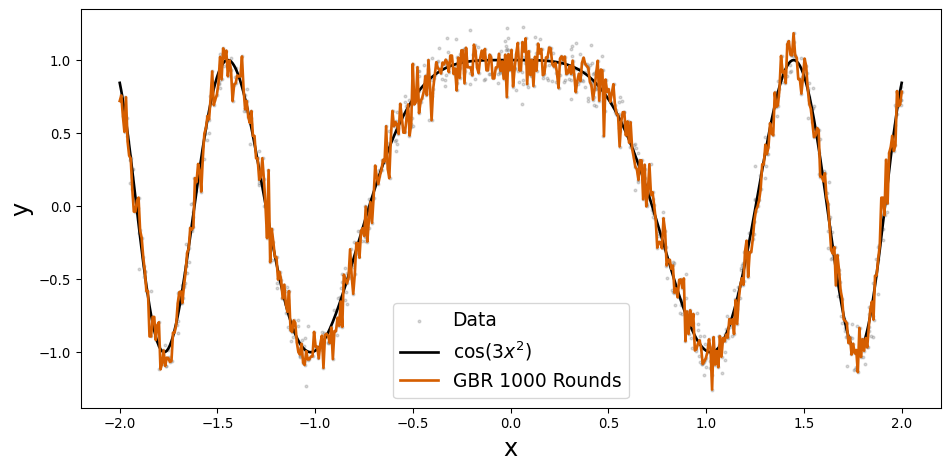
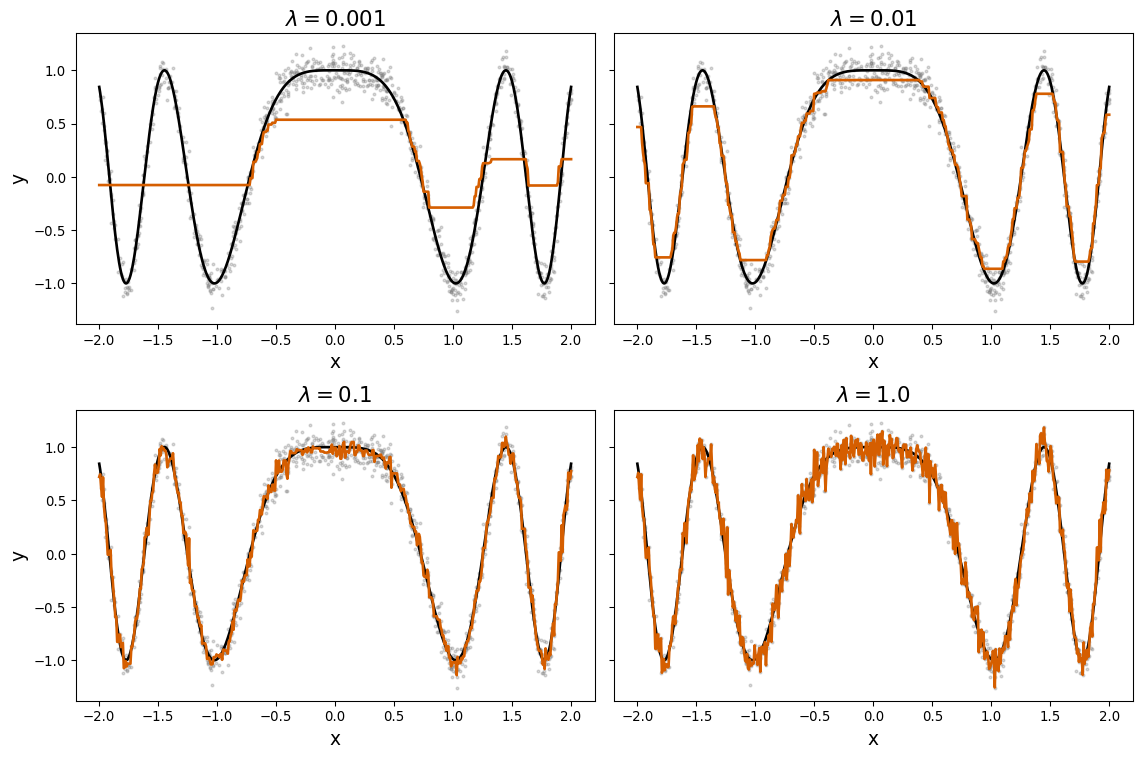
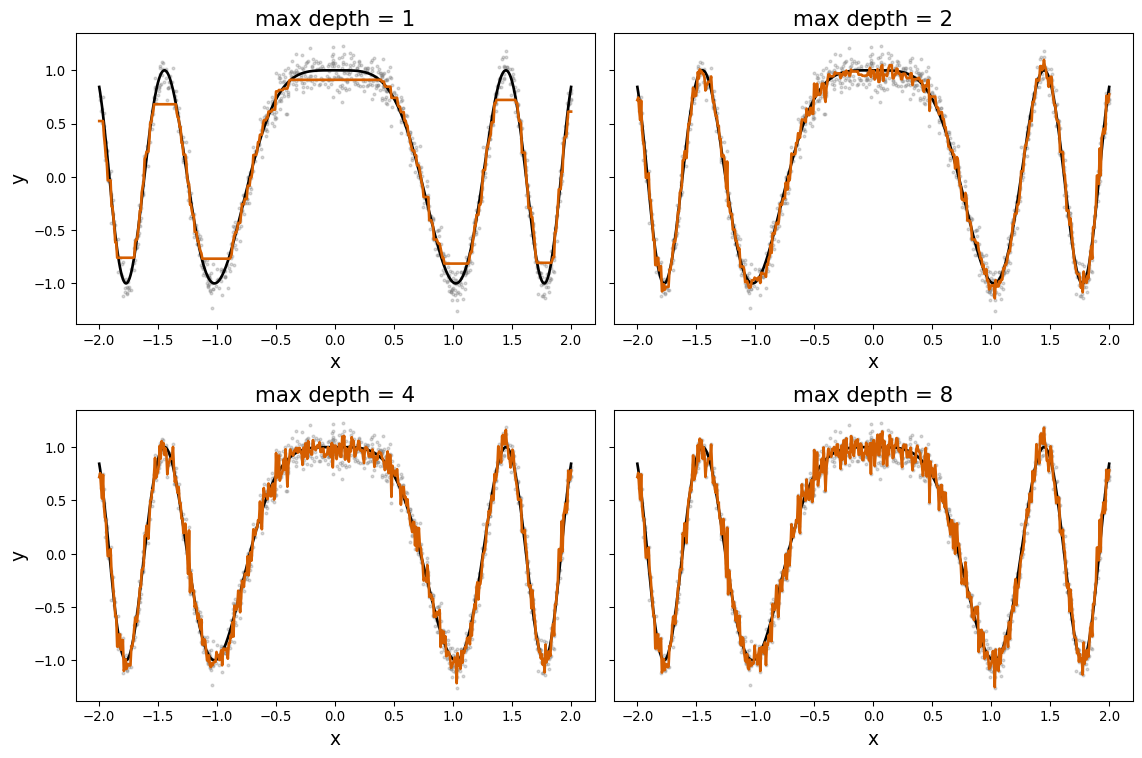
| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT3 | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 17041 | 190000.0 | 2 | 2 | 2 | 25 | 0 | 0 | 0 | 0 | 0 | ... | 23130.0 | 28126.0 | 26104.0 | 18840.0 | 1615.0 | 1200.0 | 26703.0 | 2104.0 | 7000.0 | 11747.0 |
| 8451 | 50000.0 | 1 | 2 | 2 | 40 | 0 | 0 | 0 | 0 | 0 | ... | 48600.0 | 7514.0 | 9336.0 | -177.0 | 10000.0 | 21019.0 | 1500.0 | 3000.0 | 1210.0 | 7900.0 |
| 5764 | 80000.0 | 2 | 3 | 2 | 22 | 0 | 0 | -1 | -1 | -2 | ... | 15674.0 | -1.0 | -1.0 | -1.0 | 2400.0 | 15674.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1745 | 50000.0 | 2 | 1 | 2 | 22 | 0 | 0 | 0 | 0 | 0 | ... | 50071.0 | 10104.0 | 9208.0 | 10075.0 | 2300.0 | 2000.0 | 1000.0 | 500.0 | 1000.0 | 500.0 |
| 29645 | 310000.0 | 1 | 2 | 1 | 34 | 0 | 0 | 0 | 0 | 0 | ... | 80533.0 | 70343.0 | 58365.0 | 51454.0 | 3100.0 | 3604.0 | 2366.0 | 2018.0 | 2000.0 | 1700.0 |
5 rows × 23 columns